
Introduzione
L'ingegneria dei prompt viene frequentemente descritta come un'arte, un'attività guidata dall'intuizione e dall'esperienza individuale. Il presente articolo propone una prospettiva differente: la qualità di un prompt è una grandezza misurabile, modellabile e ottimizzabile secondo principi formali. Si tratta, in sostanza, di trattare il prompt non come un testo libero, ma come una variabile indipendente il cui valore determina, in modo quantificabile, la qualità della risposta ottenuta da un modello linguistico di grandi dimensioni (LLM).
La tesi centrale di questo contributo è che la qualità di un prompt può essere espressa attraverso una funzione composita , definita come somma pesata di componenti strutturali. Tale modello non ha pretese di esaustività, ma offre un quadro operativo utile sia per la formulazione iniziale sia per il raffinamento sistematico dei prompt.
L'articolo si articola come segue: nella Sezione 1 si formalizza il concetto di prompt come variabile indipendente; nella Sezione 2 si presenta il modello di qualità con le sue cinque componenti pesate; nella Sezione 3 si analizzano le tecniche avanzate supportate dalla letteratura; nella Sezione 4 si classificano gli errori sistematici più comuni; nelle Sezioni 5 e 6 si propongono, rispettivamente, un protocollo di verifica e un approccio alla gestione sistematica della libreria di prompt.
1. Il Prompt come Variabile Indipendente
1.1 Definizione formale
Un prompt può essere definito come una sequenza di token che costituisce l'input di un modello linguistico. La risposta generata è funzione sia del prompt sia dei parametri interni del modello :
Poiché i parametri sono fissi per una data sessione di inferenza, la qualità della risposta dipende in modo diretto e prevalente dalla qualità del prompt. Si configura dunque una relazione funzionale in cui il prompt agisce come variabile indipendente e la qualità della risposta come variabile dipendente.
1.2 Evidenze empiriche
Zamfirescu-Pereira et al. [4] hanno documentato, in uno studio condotto durante CHI '23, come utenti non esperti tendano a formulare prompt vaghi, privi di struttura e di vincoli, ottenendo sistematicamente risposte di qualità inferiore rispetto a utenti che applicano principi di strutturazione. Reynolds e McDonell [5] hanno ulteriormente dimostrato che il prompting può essere concepito come una forma di programmazione: la specificità e la struttura del prompt determinano la distribuzione delle risposte possibili, restringendo lo spazio di output in modo analogo a come i vincoli di un programma definiscono il comportamento atteso.
Si osserva, in sintesi, che la relazione tra specificità del prompt e qualità della risposta non è lineare ma segue un andamento logaritmico: i primi incrementi di specificità producono miglioramenti marcati, mentre oltre una certa soglia i benefici marginali si riducono.
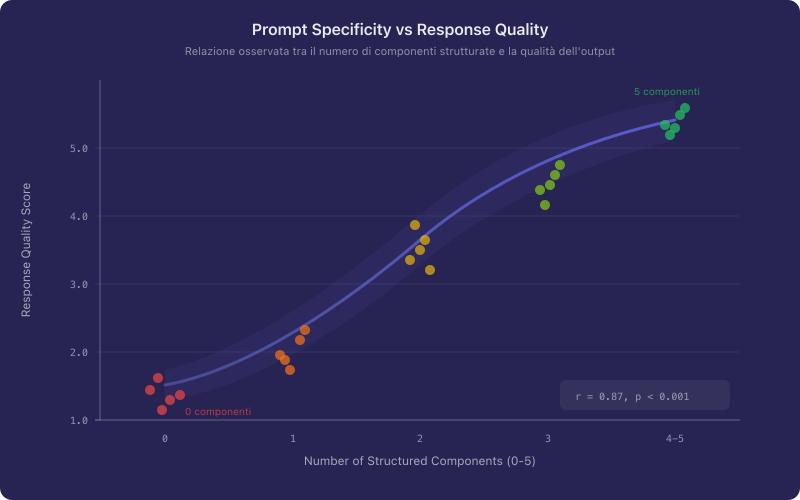
Figura 1. Rappresentazione schematica della relazione tra il grado di specificità di un prompt (asse x) e la qualità media della risposta ottenuta (asse y). Si noti l'andamento a rendimenti decrescenti oltre il punto di saturazione.
2. Un Modello di Qualità del Prompt
Si propone un modello di qualità del prompt basato su cinque componenti strutturali, ciascuna con un peso specifico che ne riflette l'importanza relativa. La qualità complessiva è definita come:
dove rappresenta il punteggio normalizzato della -esima componente e il peso associato, con il vincolo . Le cinque componenti sono: obiettivo, contesto, ruolo, formato dell'output e vincoli.
Il modello non pretende di catturare ogni sfumatura della qualità di un prompt, ma offre un framework operativo la cui utilità risiede nella sua capacità di guidare sia la costruzione sia la revisione sistematica.
2.1 Obiettivo ()
La componente con il peso maggiore è l'obiettivo. Un prompt privo di un obiettivo chiaramente definito produce risposte diffuse, generiche e difficilmente utilizzabili. White et al. [3] hanno catalogato numerosi pattern di prompt efficaci, e in tutti i casi l'elemento comune è la presenza di un obiettivo esplicito e non ambiguo.
La ragione del peso elevato è intuitiva: se (obiettivo assente o vago), il termine dominante della somma si annulla e il valore complessivo di risulta basso indipendentemente dalla qualità delle altre componenti. L'obiettivo agisce, in questo senso, come condizione necessaria.
Prompt non strutturato:
Parlami del machine learning.
Prompt strutturato:
Fornisci una spiegazione delle tre principali differenze tra apprendimento supervisionato e non supervisionato, includendo per ciascuna differenza un esempio applicativo nel settore sanitario.
Nel primo caso, lo spazio delle risposte possibili è vastissimo: il modello potrebbe generare una definizione, una storia del campo, un elenco di algoritmi o una riflessione filosofica. Nel secondo caso, l'obiettivo vincola la risposta a uno schema preciso (tre differenze, con esempi settoriali), riducendo drasticamente l'entropia dell'output.
2.2 Contesto ()
Dal punto di vista della teoria dell'informazione, il contesto opera come riduttore di entropia nello spazio degli input. Senza contesto, il modello deve inferire le condizioni al contorno della richiesta, introducendo un grado di incertezza che si propaga alla risposta. Fornire contesto equivale a restringere la distribuzione a priori delle interpretazioni possibili.
Prompt non strutturato:
Scrivi un piano di comunicazione.
Prompt strutturato:
Si consideri un'azienda SaaS B2B con 50 dipendenti, attiva nel settore della cybersecurity, che intende lanciare un nuovo prodotto per PMI nel mercato italiano. Si richiede un piano di comunicazione per i primi 90 giorni dal lancio, con un budget di 15.000 euro.
Il secondo prompt fornisce cinque elementi contestuali (tipo di azienda, settore, target, mercato, budget e orizzonte temporale) che consentono al modello di generare una risposta calibrata e pertinente, anziché generica.
2.3 Ruolo ()
L'assegnazione di un ruolo (o persona) al modello può essere interpretata come un'operazione di restringimento della distribuzione di probabilità sullo spazio delle risposte. Shanahan et al. [6], in un contributo pubblicato su Nature, hanno analizzato il fenomeno del role-play nei modelli linguistici, evidenziando come l'assegnazione di un'identità specifica modifichi in modo sistematico il registro, il vocabolario e la struttura argomentativa delle risposte generate.
Prompt non strutturato:
Come posso migliorare il mio sito web?
Prompt strutturato:
Si assuma il ruolo di un consulente senior di UX design con 15 anni di esperienza nell'ottimizzazione di siti e-commerce. Si analizzi un sito di vendita di prodotti artigianali con un tasso di conversione dello 0.8% e si propongano cinque interventi prioritari, ordinati per impatto atteso, per aumentare il tasso di conversione.
L'assegnazione del ruolo non è un espediente stilistico: determina il livello di competenza, la terminologia e la profondità analitica della risposta.
2.4 Formato dell'Output ()
Specificare il formato atteso dell'output agisce come vincolo strutturale. In assenza di indicazioni sul formato, il modello adotta la struttura che ritiene più probabile dato il contesto, che non corrisponde necessariamente a quella desiderata dall'utente.
| Formato | Descrizione | Caso d'uso ottimale |
|---|---|---|
| Elenco puntato | Elementi discreti, non ordinati | Brainstorming, raccolta di idee |
| Elenco numerato | Sequenza ordinata di passaggi | Procedure, istruzioni, ranking |
| Tabella | Dati strutturati in righe e colonne | Confronti, analisi comparative |
| Paragrafo narrativo | Testo discorsivo continuo | Spiegazioni, argomentazioni |
| JSON/YAML | Dati strutturati machine-readable | Integrazione con sistemi software |
| Codice con commenti | Blocchi di codice annotati | Sviluppo software, tutorial tecnici |
2.5 Vincoli ()
I vincoli operano come condizioni al contorno del problema. Sebbene il loro peso nel modello sia il più basso, la loro assenza può produrre risposte tecnicamente corrette ma inutilizzabili nel contesto specifico.
Esempio di vincoli espliciti:
La risposta deve rispettare i seguenti vincoli: massimo 300 parole; linguaggio accessibile a un pubblico non tecnico; nessun riferimento a prodotti o marchi specifici; inclusione di almeno un dato numerico verificabile per ogni affermazione principale.
I vincoli più efficaci sono quelli che riguardano la lunghezza, il registro linguistico, le esclusioni tematiche e i requisiti di verificabilità.

Figura 2. Distribuzione dei pesi nel modello di qualità . L'obiettivo rappresenta la componente dominante (30%), seguito dal contesto (25%), dal ruolo (20%), dal formato (15%) e dai vincoli (10%).
3. Tecniche Avanzate: Evidenze dalla Ricerca
Le tecniche presentate in questa sezione non sono alternative al modello , ma complementari. Si tratta di strategie di prompting che, applicate a un prompt già strutturato secondo il modello, possono incrementarne ulteriormente l'efficacia.
3.1 Few-shot Prompting
Brown et al. [1] hanno dimostrato, nel contributo fondamentale presentato a NeurIPS 2020, che i modelli linguistici di grandi dimensioni sono in grado di eseguire compiti dopo aver osservato solo pochi esempi forniti nel prompt stesso. Questo fenomeno, noto come in-context learning, non richiede alcun aggiornamento dei parametri del modello.
Dal punto di vista formale, il few-shot prompting opera fornendo al modello una serie di coppie per , dove è l'input di esempio e l'output atteso. Il modello inferisce il pattern e lo applica al nuovo input .
Esempio di few-shot prompting:
Si classifichino le seguenti frasi come "positivo", "negativo" o "neutro".
Frase: "Il prodotto ha superato le aspettative sotto ogni punto di vista." Classificazione: positivo
Frase: "La consegna è stata puntuale ma la confezione era danneggiata." Classificazione: neutro
Frase: "Non acquisterò mai più da questo fornitore." Classificazione: negativo
Frase: "Il rapporto qualità-prezzo è nella media del settore." Classificazione:
L'efficacia del few-shot prompting dipende dalla qualità e dalla rappresentatività degli esempi forniti. Esempi ambigui o non coerenti tra loro degradano le prestazioni anziché migliorarle.
3.2 Chain-of-Thought
Wei et al. [2] hanno dimostrato che l'inserimento di passaggi intermedi di ragionamento nel prompt migliora significativamente le prestazioni dei modelli su compiti che richiedono ragionamento logico, matematico o multi-step. La tecnica, denominata Chain-of-Thought (CoT), consiste nel richiedere esplicitamente al modello di articolare il proprio processo di ragionamento prima di fornire la risposta finale.
L'intuizione alla base del CoT è che la generazione autoregressiva token-per-token beneficia della presenza di passaggi intermedi: ogni passo funge da "memoria di lavoro" che mantiene accessibili le informazioni necessarie per il passo successivo.
Esempio di Chain-of-Thought:
Un negozio applica uno sconto del 20% su un articolo che costa 80 euro, poi un ulteriore sconto del 10% sul prezzo già scontato. Si calcoli il prezzo finale procedendo passo per passo.
Passo 1: Si calcoli il prezzo dopo il primo sconto. 80 euro x 0.80 = 64 euro. Passo 2: Si calcoli il prezzo dopo il secondo sconto. 64 euro x 0.90 = 57.60 euro. Il prezzo finale è 57.60 euro.
La semplice aggiunta dell'istruzione "si proceda passo per passo" o "si mostri il ragionamento intermedio" può migliorare le prestazioni su compiti di ragionamento in misura significativa.
3.3 Raffinamento Iterativo
Madaan et al. [7] hanno proposto il framework Self-Refine, dimostrando che i modelli linguistici possono migliorare i propri output attraverso cicli di autovalutazione e revisione. Questo principio si applica anche al prompting manuale: raramente un primo prompt produce il risultato ottimale, e il raffinamento iterativo è una componente essenziale del processo.
Si osserva tuttavia una legge dei rendimenti decrescenti. Il miglioramento marginale ottenuto alla -esima iterazione segue approssimativamente la relazione:
In termini pratici, le prime due o tre iterazioni producono i miglioramenti più sostanziali, mentre iterazioni successive tendono a produrre guadagni sempre più marginali. È possibile identificare un punto di convergenza pratica oltre il quale il costo (in termini di tempo e risorse cognitive) supera il beneficio ottenuto.
Un protocollo di raffinamento efficace prevede tre fasi per ogni iterazione:
- Valutazione: si analizza la risposta ottenuta identificando le carenze specifiche
- Diagnosi: si riconduce ogni carenza a una componente del modello
- Intervento: si modifica il prompt agendo sulla componente identificata
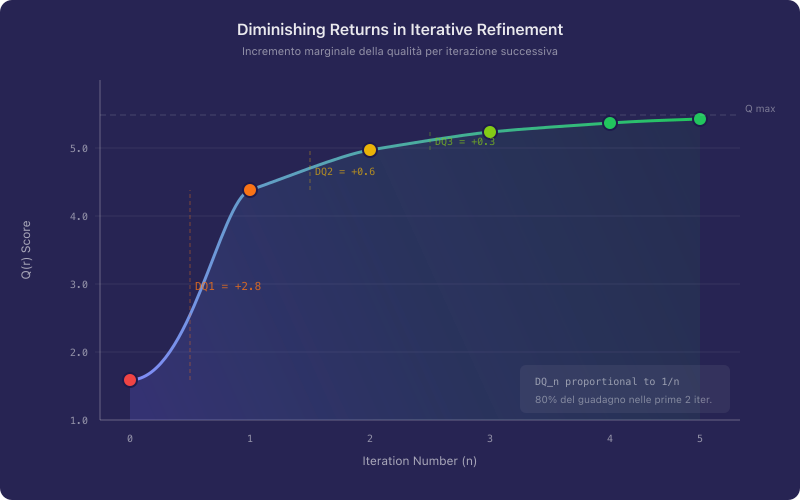
Figura 3. Andamento tipico del miglioramento di qualità in funzione del numero di iterazioni . Si noti come il guadagno marginale si riduca approssimativamente come , suggerendo che nella pratica tre o quattro iterazioni rappresentano il compromesso ottimale.
4. Errori Sistematici nella Formulazione dei Prompt
L'analisi delle pratiche di prompting più comuni consente di identificare una tassonomia di errori ricorrenti. La tabella seguente classifica sei errori sistematici, ne descrive l'impatto sul modello e propone per ciascuno una strategia di mitigazione.
| Errore | Descrizione | Impatto su | Strategia di mitigazione |
|---|---|---|---|
| Vaghezza dell'obiettivo | L'obiettivo è assente, implicito o formulato in modo ambiguo | , riduzione fino al 30% di | Formulare l'obiettivo come azione specifica e verificabile con verbi come "elenca", "confronta", "calcola" |
| Verbosità senza contenuto | Il prompt contiene molte parole ma poche informazioni utili | Rumore che degrada e | Applicare il principio di economia: ogni frase deve apportare informazione non ridondante |
| Contraddizioni interne | Il prompt contiene istruzioni mutuamente incompatibili | Ambiguità nella funzione obiettivo, output incoerente | Rileggere il prompt verificando la coerenza logica tra tutti i vincoli e le istruzioni |
| Formato non specificato | Nessuna indicazione sulla struttura dell'output desiderato | , output in formato arbitrario | Dichiarare esplicitamente il formato atteso (tabella, elenco, paragrafo, JSON) |
| Contesto insufficiente | Mancano informazioni sul dominio, il pubblico o le condizioni al contorno | , risposta generica e non calibrata | Includere almeno: dominio di applicazione, destinatario e vincoli principali |
| Assenza di iterazione | Il primo output viene accettato senza revisione del prompt | subottimale, opportunità di miglioramento non sfruttate | Pianificare almeno due o tre cicli di raffinamento secondo il protocollo valutazione-diagnosi-intervento |
Si noti che questi errori non sono mutuamente esclusivi: un prompt può presentarne simultaneamente più di uno, con effetti cumulativi sulla degradazione di .
5. Protocollo di Verifica
Si propone un protocollo di verifica strutturato in sette punti, ciascuno mappato a una o più componenti del modello . Il protocollo è concepito per essere applicato prima dell'invio del prompt al modello.
-
Verifica dell'obiettivo (). L'obiettivo è esplicito, specifico e non ambiguo? È possibile determinare, leggendo solo l'obiettivo, se la risposta del modello sarà soddisfacente o meno?
-
Verifica del contesto (). Sono state fornite tutte le informazioni di dominio necessarie? Il pubblico destinatario è identificato? Le condizioni al contorno sono definite?
-
Verifica del ruolo (). È stato assegnato un ruolo al modello? Il ruolo è coerente con l'obiettivo e il livello di competenza richiesto nella risposta?
-
Verifica del formato (). È stato specificato il formato dell'output? Il formato richiesto è appropriato per il tipo di contenuto atteso?
-
Verifica dei vincoli (). Sono presenti vincoli su lunghezza, registro, esclusioni o requisiti specifici? I vincoli sono compatibili tra loro e con l'obiettivo?
-
Verifica di coerenza interna. Il prompt nel suo complesso è privo di contraddizioni? Tutte le istruzioni sono logicamente compatibili?
-
Pianificazione dell'iterazione. È stato previsto almeno un ciclo di raffinamento? Sono stati identificati i criteri per valutare la qualità della risposta?
L'applicazione sistematica di questo protocollo consente di identificare e correggere le carenze strutturali di un prompt prima che si manifestino nella risposta, riducendo il numero di iterazioni necessarie per convergere a un output soddisfacente.
6. Gestione Sistematica della Libreria di Prompt
6.1 Dal prompt singolo alla libreria
La formulazione di un singolo prompt efficace è una condizione necessaria ma non sufficiente per un utilizzo produttivo dei modelli linguistici. Man mano che il numero di prompt utilizzati cresce, emergono esigenze di organizzazione, categorizzazione e riuso che richiedono un approccio sistematico.
Liu et al. [8], in una survey pubblicata su ACM Computing Surveys, hanno evidenziato come il prompting sia diventato un paradigma centrale nell'interazione con i modelli linguistici, e come la gestione efficace dei prompt rappresenti un fattore critico per la produttività. Si tratta, in sostanza, di un problema di gestione della conoscenza: i prompt efficaci incorporano conoscenza procedurale che, se non organizzata, viene perduta o duplicata.
6.2 Requisiti di un sistema di gestione
Un sistema di gestione dei prompt dovrebbe soddisfare i seguenti requisiti funzionali:
- Categorizzazione: possibilità di organizzare i prompt per dominio, tipo di compito o progetto
- Tagging: etichettatura flessibile per facilitare il recupero trasversale
- Versionamento: tracciamento delle modifiche nel tempo, con possibilità di confrontare e ripristinare versioni precedenti
- Valutazione della qualità: integrazione di metriche oggettive (come il modello proposto) per monitorare la qualità della libreria
- Condivisione: possibilità di condividere prompt efficaci all'interno di un team
6.3 Strumenti disponibili
La piattaforma Keep My Prompts è stata progettata specificamente per rispondere a queste esigenze. Offre funzionalità di categorizzazione con colori personalizzati, tagging flessibile, cronologia delle versioni con confronto visuale tra revisioni, e un sistema di valutazione automatica della qualità basato su intelligenza artificiale che analizza i prompt secondo criteri analoghi a quelli presentati in questo articolo. Per i team di lavoro sono disponibili piani collaborativi che consentono la gestione condivisa di librerie di prompt con tracciamento delle modifiche per autore.
L'adozione di un sistema di gestione strutturato trasforma i prompt da artefatti effimeri a risorse organizzative riutilizzabili, con benefici misurabili in termini di efficienza e coerenza dei risultati.
7. Conclusioni e Raccomandazione Operativa
7.1 Sintesi
Il presente articolo ha proposto un approccio formale alla valutazione e alla costruzione dei prompt per modelli linguistici di grandi dimensioni. Il modello scompone la qualità di un prompt in cinque componenti pesate — obiettivo, contesto, ruolo, formato e vincoli — offrendo un framework operativo per la costruzione, la valutazione e il raffinamento sistematico.
Si è inoltre dimostrato, con il supporto della letteratura scientifica, che tecniche avanzate come il few-shot prompting [1], il chain-of-thought [2] e il raffinamento iterativo [7] producono miglioramenti misurabili quando applicate a prompt già strutturati secondo il modello proposto.
7.2 Raccomandazione operativa
Sulla base dell'analisi condotta, si formula la seguente raccomandazione: prima di inviare qualsiasi prompt a un modello linguistico, si verifichi che almeno tre delle cinque componenti del modello siano esplicitamente presenti, dando priorità all'obiettivo () e al contesto ().
Questa regola, che si potrebbe definire "regola del 3 su 5", garantisce un valore minimo di superiore a 0.55 anche nell'ipotesi conservativa in cui le componenti presenti ricevano un punteggio . Nella pratica, ciò si traduce in una significativa riduzione delle iterazioni necessarie e in un aumento della probabilità di ottenere una risposta utilizzabile al primo tentativo.
7.3 Prospettive
Il campo del prompt engineering è in rapida evoluzione. L'emergere di tecniche come il prompting automatico, l'ottimizzazione dei prompt mediante algoritmi di ricerca e l'integrazione di strumenti di valutazione basati su intelligenza artificiale suggerisce che la disciplina si stia progressivamente spostando da un approccio artigianale a uno ingegneristico. Il modello rappresenta un contributo in questa direzione: un primo passo verso la formalizzazione di una pratica che, per la sua pervasività e il suo impatto, merita rigore metodologico.
Riferimenti Bibliografici
[1] Brown, T. et al. (2020). "Language Models are Few-Shot Learners." Advances in Neural Information Processing Systems, 33, 1877-1901.
[2] Wei, J. et al. (2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." Advances in Neural Information Processing Systems, 35.
[3] White, J. et al. (2023). "A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT." arXiv preprint arXiv:2302.11382.
[4] Zamfirescu-Pereira, J.D. et al. (2023). "Why Johnny Can't Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts." Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems.
[5] Reynolds, L. & McDonell, K. (2021). "Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm." Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems.
[6] Shanahan, M. et al. (2023). "Role-Play with Large Language Models." Nature, 623, 493-498.
[7] Madaan, A. et al. (2023). "Self-Refine: Iterative Refinement with Self-Feedback." Advances in Neural Information Processing Systems, 36.
[8] Liu, P. et al. (2023). "Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing." ACM Computing Surveys, 55(9), 1-35.