
Introduction
Anyone who works with language models regularly has encountered this situation: one prompt works perfectly, another — seemingly similar — produces mediocre results. The difference is real, but the diagnosis is elusive. Without a structured evaluation system, improving prompts becomes a trial-and-error process driven by intuition rather than analysis.
The problem is not new. In technical writing, software engineering, and scientific research, every mature discipline has developed metrics for evaluating the quality of its output. Prompt engineering, while still an emerging discipline, has reached a level of complexity that demands the same rigor.
This article proposes a quantitative prompt evaluation model based on six independent criteria, each supported by experimental evidence. The model, implemented in the Prompt Score system by Keep My Prompts, assigns each prompt a score from 1 to 5 on each criterion and a weighted overall score, providing an immediate diagnostic of strengths and weaknesses.
The goal is not to replace the user's judgment but to make it more informed. A prompt scoring 2.3 on "Clarity" is not necessarily a bad prompt — it is a prompt that could benefit from more specific formulation. The difference between qualitative feedback ("improve the prompt") and dimensional quantitative feedback ("clarity is 2.3/5, try specifying the output format") is the difference between generic advice and an operational diagnostic.
1. Why Measure Prompt Quality
1.1 The Problem with Subjective Evaluation
Prompt quality is typically assessed indirectly: one looks at the generated response and, if it is satisfactory, assumes the prompt was "good." This approach has three fundamental limitations.
First, it conflates correlation and causation. A good response may result from a mediocre prompt if the model has particularly rich training data for that domain. Conversely, an excellent prompt may generate mediocre responses if the task is inherently ambiguous or the model has specific limitations [1].
Second, it is non-repeatable. The same prompt, submitted to the same model at different times, can produce significantly different responses (unless temperature is set to 0). Evaluating a prompt through a single response is like evaluating a die by rolling it once.
Third, it does not scale. A professional managing dozens or hundreds of prompts cannot evaluate them one by one by executing them and reading the responses. What is needed is a system that provides rapid assessment based on the structural properties of the prompt itself, independent of the response.
1.2 The Code Review Analogy
The parallel with software engineering is illuminating. In code review, code is evaluated before execution based on structural properties: readability, pattern adherence, error handling, test coverage. No competent reviewer would say "the code is good because the program runs" — because poorly structured code can work under normal conditions and fail under unforeseen ones.
The same principle applies to prompts. A well-structured prompt is not merely more likely to produce good results: it is more robust (works across different models), more maintainable (what it does and why is clear), and more composable (can be integrated into more complex workflows).
1.3 The Dimensions of Quality
The prompt engineering literature has identified several structural properties that correlate with response quality. Schulhoff et al. [2], in the most extensive survey to date (4,247 records analyzed), cataloged 58 techniques groupable into categories that map directly onto quality dimensions. Bsharat et al. [3] systematized 26 principles for effective prompting, tested on LLaMA and GPT-3.5/4 with consistent improvements.
The challenge is not identifying the dimensions — the literature has already done so — but integrating them into a coherent, weighted, and actionable evaluation system.
2. The Six Evaluation Criteria
The Prompt Score model evaluates each prompt on six independent criteria. Each criterion receives a score from 1 to 5, where 1 indicates total absence and 5 indicates excellence. The criteria were selected based on three requirements: (a) experimental evidence of impact on response quality, (b) mutual independence (evaluating one does not imply information about the others), (c) direct observability in the prompt text (without needing to execute it).
2.1 Clarity and Specificity
| Score | Description | Example |
|---|---|---|
| 1 | Vague, ambiguous, open to multiple interpretations | "Tell me about marketing" |
| 3 | Clear but generic, lacks specific details | "Write a marketing plan for an e-commerce" |
| 5 | Precise, with explicit action, subject, constraints, and criteria | "Write a marketing plan for an organic cosmetics e-commerce, target 25-40, budget $3,000/month, focus on Instagram and email" |
Clarity is the criterion with the greatest individual impact on response quality. Zhou et al. [4] demonstrated that automatic optimization of the instruction formulation produces prompts that match or surpass those written by human experts on 21 out of 24 tasks. Mishra et al. [5] showed that structured reformulation of instructions improves GPT-3 performance by 12.5% on average.
High score indicators: explicit action verbs, defined subject and object, quantitative constraints (length, number of elements, format), specified quality criteria.
2.2 Context
| Score | Description | Example |
|---|---|---|
| 1 | No background information | "Write a newsletter" |
| 3 | Partial context, missing key elements | "Write a newsletter for my tech company" |
| 5 | Rich context with audience, domain, constraints, and objective | "Write a newsletter for a B2B SaaS startup, 500 subscribers, CTOs and senior developers, technical but accessible tone, goal: introduce the new API versioning feature" |
Context operates as conditioning information that narrows the space of possible interpretations. Brown et al. [6], in the foundational GPT-3 paper, established that the quantity and quality of contextual information directly determine model performance — the principle of "in-context learning."
A crucial point: context must be specific and relevant. Zheng et al. [7] demonstrated that generic personas in system prompts ("you are a helpful assistant") do not improve performance on factual tasks. Effective context provides information that the model could not infer on its own.
2.3 TCOF Structure
| Score | Description |
|---|---|
| 1 | A single unstructured block of text |
| 3 | Some components present, but organization is lacking |
| 5 | All four TCOF components clearly articulated: Task, Context, Output, Format |
The TCOF framework (Task, Context, Output, Format) decomposes the prompt into four functional components, each with a distinct impact on response quality. Article 1.5 on this blog provides a complete analysis with experimental evidence.
Yin et al. [8] conducted a systematic sensitivity analysis of models to different instruction components, demonstrating that removing output specifications produces the most pronounced performance drop. The finding confirms that explicit structuring is not a formalism but a mechanism that reduces output entropy.

Figure 1. The six criteria of the Prompt Score model. Each criterion evaluates an independent dimension of prompt quality, from the foundational level (Clarity) to the advanced level (Chain-of-Thought). The weights reflect the relative impact on the quality of the generated response.
2.4 Role Prompting
| Score | Description | Example |
|---|---|---|
| 1 | No role assigned | "Analyze this sales data" |
| 3 | Generic role | "You are a business expert. Analyze this sales data" |
| 5 | Specific role with expertise and perspective | "You are a senior data analyst specializing in B2C e-commerce with 10 years of experience in seasonal performance analysis. Analyze this Q4 sales data identifying anomalous patterns against industry benchmarks" |
Kong et al. [9], at NAACL 2024, demonstrated that role-play prompting improves accuracy on reasoning benchmarks from 53.5% to 63.8% (AQuA) and from 23.8% to 84.2% (Last Letter). The improvement is not marginal — it is an order of magnitude for some tasks.
Role prompting works because it modifies the model's response distribution, activating knowledge and linguistic patterns associated with the specified profile. The more specific the role — with defined domain, experience, and perspective — the greater the effect.
2.5 Few-Shot Examples
| Score | Description |
|---|---|
| 1 | No examples provided |
| 3 | One example present, but generic or unrepresentative |
| 5 | 2-3 specific examples clearly showing expected input and desired output |
Brown et al. [6] demonstrated that few-shot prompting — providing input-output examples — is the fundamental mechanism of in-context learning. The model learns the pattern from examples without parameter updates.
The effectiveness of few-shot depends on example quality more than quantity. Wei et al. [10] showed that for reasoning tasks, even a single example with an explicit chain of reasoning outperforms many examples without reasoning.
When essential: tasks with non-standard output formats, classifications with domain-specific categories, text-to-text transformations with implicit rules.
2.6 Chain-of-Thought
| Score | Description |
|---|---|
| 1 | No encouragement for step-by-step reasoning |
| 3 | Generic indication ("think step by step") |
| 5 | Explicit reasoning structure with defined steps ("First analyze X, then evaluate Y, finally conclude Z") |
Kojima et al. [11] demonstrated that adding "Let's think step by step" is sufficient to raise accuracy on MultiArith from 17.7% to 78.7% in zero-shot mode. Wei et al. [10] then formalized chain-of-thought prompting, showing significant improvements on arithmetic, symbolic reasoning, and common-sense tasks.
Chain-of-thought is not useful for all prompts. It is particularly effective for: tasks requiring multi-step reasoning, comparative analyses, complex problem solving, and tasks where the model tends to "jump" to conclusions without showing the process.
3. The Weighting Model
3.1 Relative Weights
Not all criteria have the same impact on response quality. The Prompt Score model adopts evidence-based weighting:
| Criterion | Weight | Rationale |
|---|---|---|
| Clarity and Specificity | 0.25 | Primary performance determinant [4][5] |
| Context | 0.20 | Reduces interpretation entropy [6] |
| TCOF Structure | 0.20 | Ensures structural completeness [8] |
| Role Prompting | 0.15 | Effective but not always necessary [9] |
| Chain-of-Thought | 0.10 | Crucial for complex tasks, less so for simple ones [10][11] |
| Few-Shot Examples | 0.10 | Powerful but optional for many tasks [6] |
The overall score is calculated as a weighted average:
where is the weight of criterion and is the assigned score (1-5). The result is a value in .
3.2 Score Interpretation
| Range | Interpretation | Suggested Action |
|---|---|---|
| 4.0 - 5.0 | Excellent | The prompt is well-structured. Any improvements are marginal. |
| 3.0 - 3.9 | Good | Solid foundation, but some dimensions are underdeveloped. |
| 2.0 - 2.9 | Needs Improvement | Important elements are missing. Follow the per-criterion suggestions. |
| 1.0 - 1.9 | Insufficient | Restructuring needed. Start with clarity and context. |
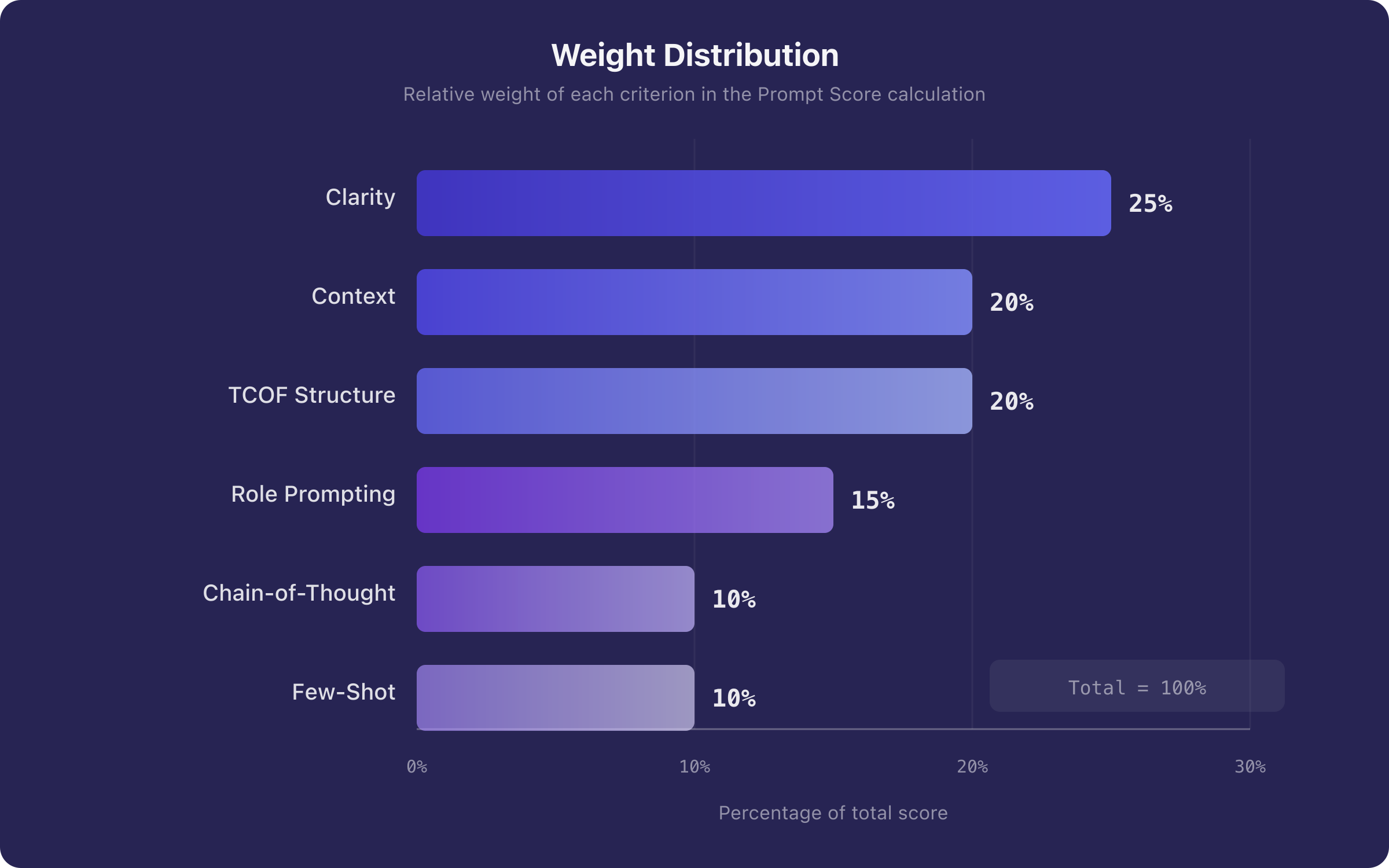
Figure 2. Weight distribution in the Prompt Score model. The weights reflect the relative impact of each criterion on response quality, based on experimental evidence from the literature.
3.3 Why Weighting Is Not Uniform
A legitimate question is: why not assign equal weight to all criteria? The answer lies in the asymmetry of impacts.
A prompt with clarity 1/5 but chain-of-thought 5/5 will almost certainly produce poor results: the model will reason step by step, but on a poorly defined task. Conversely, a prompt with clarity 5/5 and chain-of-thought 1/5 will produce good results for simple tasks and acceptable results for complex ones.
The weighting captures this asymmetry: foundational criteria (clarity, context, structure) carry higher weights because their impact is universal. Advanced criteria (role prompting, few-shot, chain-of-thought) carry lower weights because their impact is conditional — it depends on the task type.
4. Case Study: From Analysis to Improvement
4.1 The Initial Prompt
Consider a real prompt for marketing content generation:
Write a LinkedIn post about our new AI feature. It should be engaging and professional.
Let us submit it to Prompt Score analysis:
| Criterion | Score | Diagnosis |
|---|---|---|
| Clarity | 2/5 | "LinkedIn post" is generic. Missing: length, type (text, carousel), desired CTA |
| Context | 1/5 | No information about the company, the feature, or the target audience |
| TCOF Structure | 2/5 | Task present but vague. C, O, F are missing |
| Role Prompting | 1/5 | No role assigned |
| Few-Shot | 1/5 | No examples of previous posts |
| Chain-of-Thought | 1/5 | No reasoning structure |
| Overall | 1.5/5 |
4.2 Score-Guided Improvement
Following the indications from the lowest-scoring criteria (context: 1/5, role: 1/5), the prompt is reformulated:
[Role] You are a senior copywriter specializing in B2B SaaS communications on LinkedIn, with experience in the tech industry.
[Task] Write a LinkedIn post to announce a new product feature.
[Context] The company is Keep My Prompts, a platform for organizing and optimizing AI prompts. The new feature is the "Prompt Score System": an automated evaluation system that analyzes prompts on 6 criteria and assigns a score from 1 to 5. The target audience is professionals who use ChatGPT, Claude, or Gemini daily for work.
[Output] The post should: capture attention in the first 2 lines (hook), explain the benefit in 3-4 lines, include a concrete example, and conclude with a clear CTA. Tone: professional but accessible, with a touch of enthusiasm. Length: 150-200 words.
[Format] Use short paragraphs (1-2 sentences each). Include 2-3 strategic emojis. Add 3-5 relevant hashtags at the end.
New analysis:
| Criterion | Before | After | Change |
|---|---|---|---|
| Clarity | 2/5 | 5/5 | +3 |
| Context | 1/5 | 5/5 | +4 |
| TCOF Structure | 2/5 | 5/5 | +3 |
| Role Prompting | 1/5 | 5/5 | +4 |
| Few-Shot | 1/5 | 1/5 | 0 |
| Chain-of-Thought | 1/5 | 1/5 | 0 |
| Overall | 1.5/5 | 3.9/5 | +2.4 |
The overall score went from 1.5 to 3.9, a 160% improvement. The two criteria remaining at 1/5 (few-shot and chain-of-thought) are not necessarily a problem: for a LinkedIn post, examples are useful but not essential, and chain-of-thought is not required for creative text generation.
4.3 The Lesson
The value of the scoring system lies not in the absolute score but in the diagnostic. The initial prompt scored 1.5 not because it was "wrong," but because it lacked information that the model could not infer on its own. The scoring system identified exactly which dimensions were missing (context, role), enabling targeted improvement.
5. Scoring and Iteration: The Improvement Cycle
5.1 The Prompt as an Iterative Artifact
A common mistake is treating the prompt as a static artifact: written once and used repeatedly. In reality, the most effective prompts are the result of successive iterations, each informed by the response feedback and — with a scoring system — by structural feedback.
The ideal improvement cycle is:
- Write the initial prompt
- Score with the evaluation system
- Identify the lowest-scoring criteria
- Improve those specific criteria
- Re-evaluate and compare with the previous version
- Save the version with the score as a snapshot
5.2 The Value of Historical Tracking
When the score is saved alongside each version of the prompt, a powerful pattern emerges: one can see the evolution of quality over time. A prompt that starts at 2.1 and after three iterations reaches 4.2 tells a story of measurable improvement.
This approach is particularly valuable in teams, where different members can contribute to prompt improvement. The score serves as a lingua franca: "the prompt went from 2.3 to 4.1" is objective information, not a subjective judgment.
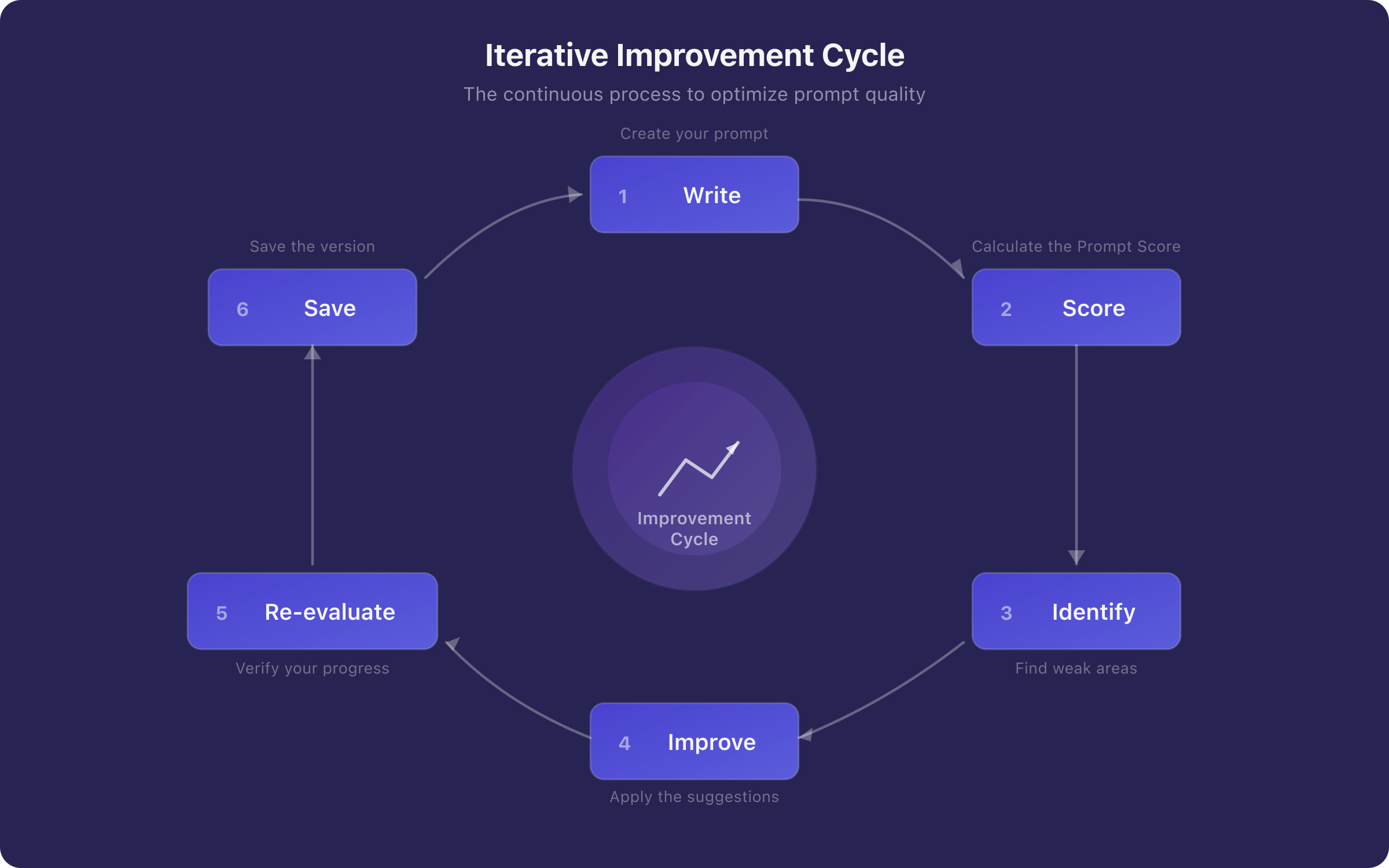
Figure 3. The iterative prompt improvement cycle driven by Prompt Score. Each iteration is informed by per-criterion diagnostics, enabling targeted improvements. Historical version tracking with score snapshots makes the quality evolution visible.
6. Limitations and Caveats
6.1 What the Score Does Not Measure
The scoring system evaluates the structural properties of the prompt, not its effectiveness for a specific task. A prompt scoring 5/5 on all criteria could still produce mediocre results if:
- The task is inherently beyond the model's capabilities
- The domain is outside the training data distribution
- The instructions are internally contradictory (the score detects structure, not semantic coherence)
6.2 The Score Is Not Absolute
A prompt scoring 2.5 is not necessarily "worse" than one scoring 4.0 in an operational sense. The context of use matters: a quick brainstorming prompt does not need the same level of structuring as a report generation prompt. The score indicates the degree of structuring, not intrinsic value.
6.3 The Risk of Over-Engineering
There is a point of diminishing returns: adding context, examples, and structure beyond a certain level does not improve the response and may even confuse the model. Liu et al. [12] documented the "lost in the middle" phenomenon: information positioned in the central portion of a long prompt is utilized less effectively. Context quality matters more than quantity.
7. Tools for Prompt Evaluation
7.1 Manual Evaluation
Manual evaluation is possible and formative: take the prompt, assign a score from 1 to 5 for each criterion, and calculate the weighted average. The process takes 2-3 minutes but develops a structured intuition for prompt quality.
7.2 Automated Evaluation
For those managing many prompts or wanting immediate feedback, automated evaluation is the natural choice. The Prompt Score System by Keep My Prompts implements the model described in this article:
- Evaluation on 6 criteria with a 1-5 score for each
- Weighted overall score using the formula
- Visual V-Meter with color coding (red to green) for immediate feedback
- Targeted suggestions: an actionable tip to improve the weakest area
- Version snapshots: the score is saved with each prompt version, creating a historical quality trail
- Automatic scoring on save: every time you save a prompt, the score is recalculated
The advantage of automated evaluation is not just speed — it is consistency. A human evaluator can be influenced by familiarity with the prompt, the context of the moment, or fatigue. The automated system applies the same criteria, with the same weights, every time.
Conclusion
Quantitative prompt evaluation is not an academic exercise — it is an operational tool that transforms an intuitive process into a structured one. The six criteria of the Prompt Score model — clarity, context, TCOF structure, role prompting, few-shot, chain-of-thought — capture the fundamental dimensions of prompt quality, each supported by experimental evidence from the literature.
The main message of this article is not "use the scoring system," but "start thinking about prompts as measurable artifacts." Whether using an automated system or manual evaluation, the simple act of asking "how clear is this prompt?" or "have I provided sufficient context?" systematically improves output quality.
The best prompts are not born from inspiration. They are born from informed iteration.
References
[1] Anthropic, "Prompt Engineering Guide," Claude Documentation, 2024.
[2] E. Schulhoff et al., "The Prompt Report: A Systematic Survey of Prompting Techniques," arXiv:2406.06608, 2024.
[3] S. M. Bsharat et al., "Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4," arXiv:2312.16171, 2023.
[4] Y. Zhou et al., "Large Language Models Are Human-Level Prompt Engineers," ICLR, 2023.
[5] S. Mishra et al., "Reframing Instructional Prompts to GPTk's Language," Findings of ACL, 2022.
[6] T. B. Brown et al., "Language Models are Few-Shot Learners," NeurIPS, 2020.
[7] C. Zheng et al., "Is 'A Helpful Assistant' the Best Role for LLMs? A Systematic Evaluation of LLM Role-Playing," Findings of EMNLP, 2024.
[8] F. Yin et al., "Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning," ACL, 2023.
[9] X. Kong et al., "Better Zero-Shot Reasoning with Role-Play Prompting," NAACL, 2024.
[10] J. Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," NeurIPS, 2022.
[11] T. Kojima et al., "Large Language Models are Zero-Shot Reasoners," NeurIPS, 2022.
[12] N. F. Liu et al., "Lost in the Middle: How Language Models Use Long Contexts," Transactions of the ACL, 2024.