
Introduzione
Chiunque utilizzi modelli linguistici con regolarità si è trovato in questa situazione: un prompt funziona perfettamente, un altro — apparentemente simile — produce risultati mediocri. La differenza è reale, ma la diagnosi è sfuggente. Senza un sistema di valutazione strutturato, migliorare i prompt diventa un processo per tentativi, dominato dall'intuizione piuttosto che dall'analisi.
Il problema non è nuovo. Nella scrittura tecnica, nel software engineering, nella ricerca scientifica, ogni disciplina matura ha sviluppato metriche per valutare la qualità del proprio output. Il prompt engineering, pur essendo una disciplina emergente, ha raggiunto un livello di complessità che richiede lo stesso rigore.
Il presente articolo propone un modello di valutazione quantitativa dei prompt basato su sei criteri indipendenti, ciascuno con evidenze sperimentali a supporto. Il modello, implementato nel sistema Prompt Score di Keep My Prompts, assegna a ogni prompt un punteggio da 1 a 5 su ciascun criterio e un punteggio complessivo ponderato, fornendo una diagnostica immediata delle aree di forza e di debolezza.
L'obiettivo non è sostituire il giudizio dell'utente, ma renderlo più informato. Un prompt con punteggio 2.3 in "Chiarezza" non è necessariamente un cattivo prompt — è un prompt che potrebbe beneficiare di una formulazione più specifica. La differenza tra feedback qualitativo ("migliora il prompt") e feedback quantitativo dimensionale ("la chiarezza è 2.3/5, prova a specificare il formato di output") è la differenza tra un consiglio generico e una diagnosi operativa.
1. Perché Misurare la Qualità di un Prompt
1.1 Il problema della valutazione soggettiva
La qualità di un prompt viene tipicamente valutata in modo indiretto: si guarda la risposta generata e, se questa è soddisfacente, si assume che il prompt fosse "buono". Questo approccio presenta tre limiti fondamentali.
Primo, confonde correlazione e causalità. Una risposta buona può derivare da un prompt mediocre se il modello ha dati di addestramento particolarmente ricchi per quel dominio. Viceversa, un prompt eccellente può generare risposte mediocri se il task è intrinsecamente ambiguo o se il modello ha limitazioni specifiche [1].
Secondo, è non ripetibile. Lo stesso prompt, sottoposto allo stesso modello in momenti diversi, può produrre risposte significativamente diverse (a meno che la temperatura non sia impostata a 0). Valutare il prompt attraverso una singola risposta è come valutare un dado lanciandolo una volta sola.
Terzo, è non scalabile. Un professionista che gestisce decine o centinaia di prompt non può valutarli uno per uno eseguendoli e leggendo le risposte. Serve un sistema che fornisca una valutazione rapida basata sulle proprietà strutturali del prompt stesso, indipendentemente dalla risposta.
1.2 L'analogia con il code review
Il parallelo con il software engineering è illuminante. Nel code review, il codice viene valutato prima dell'esecuzione sulla base di proprietà strutturali: leggibilità, aderenza ai pattern, gestione degli errori, copertura dei test. Nessun reviewer competente direbbe "il codice è buono perché il programma funziona" — perché un codice mal strutturato può funzionare in condizioni normali e fallire in condizioni impreviste.
Lo stesso principio si applica ai prompt. Un prompt ben strutturato non è solo più probabile di produrre buoni risultati: è più robusto (funziona con modelli diversi), più manutenibile (è chiaro cosa fa e perché), e più componibile (può essere integrato in workflow più complessi).
1.3 Le dimensioni della qualità
La letteratura sul prompt engineering ha identificato diverse proprietà strutturali che correlano con la qualità della risposta. Schulhoff et al. [2], nella survey più estesa a oggi disponibile (4.247 record analizzati), hanno catalogato 58 tecniche raggruppabili in categorie che mappano direttamente sulle dimensioni di qualità. Bsharat et al. [3] hanno sistematizzato 26 principi per il prompting efficace, testati su LLaMA e GPT-3.5/4 con miglioramenti consistenti.
La sfida non è identificare le dimensioni — la letteratura le ha già identificate — ma integrarle in un sistema di valutazione coerente, ponderato e azionabile.
2. I Sei Criteri di Valutazione
Il modello Prompt Score valuta ogni prompt su sei criteri indipendenti. Ogni criterio riceve un punteggio da 1 a 5, dove 1 indica assenza totale e 5 indica eccellenza. I criteri sono stati selezionati sulla base di tre requisiti: (a) evidenza sperimentale dell'impatto sulla qualità della risposta, (b) indipendenza reciproca (valutare uno non implica informazioni sugli altri), (c) osservabilità diretta nel testo del prompt (senza necessità di eseguirlo).
2.1 Chiarezza e Specificità
| Punteggio | Descrizione | Esempio |
|---|---|---|
| 1 | Vago, ambiguo, interpretabile in modi multipli | "Parlami del marketing" |
| 3 | Chiaro ma generico, manca di dettagli specifici | "Scrivi un piano di marketing per un e-commerce" |
| 5 | Preciso, con azione, soggetto, vincoli e criteri espliciti | "Scrivi un piano di marketing per un e-commerce di cosmetici bio, target 25-40 anni, budget 3.000€/mese, focus su Instagram e email" |
La chiarezza è il criterio con il maggiore impatto individuale sulla qualità della risposta. Zhou et al. [4] hanno dimostrato che l'ottimizzazione automatica della formulazione dell'istruzione produce prompt che eguagliano o superano quelli scritti da esperti umani in 21 task su 24. Mishra et al. [5] hanno mostrato che la riformulazione strutturata delle istruzioni migliora le prestazioni di GPT-3 del 12,5% in media.
Indicatori di punteggio alto: verbi d'azione espliciti, soggetto e oggetto definiti, vincoli quantitativi (lunghezza, numero di elementi, formato), criteri di qualità specificati.
2.2 Contesto
| Punteggio | Descrizione | Esempio |
|---|---|---|
| 1 | Nessuna informazione di background | "Scrivi una newsletter" |
| 3 | Contesto parziale, mancano elementi chiave | "Scrivi una newsletter per la mia azienda tech" |
| 5 | Contesto ricco con audience, dominio, vincoli e obiettivo | "Scrivi una newsletter per una startup SaaS B2B, 500 iscritti, CTO e developer senior, tono tecnico ma accessibile, obiettivo: presentare la nuova feature di API versioning" |
Il contesto opera come informazione condizionante che restringe lo spazio delle interpretazioni possibili. Brown et al. [6], nel paper fondamentale su GPT-3, hanno stabilito che la quantità e qualità delle informazioni contestuali determinano direttamente la performance del modello — il principio dell'"in-context learning".
Un punto cruciale: il contesto deve essere specifico e rilevante. Zheng et al. [7] hanno dimostrato che le persona generiche nei system prompt ("sei un assistente utile") non migliorano le prestazioni su task fattuali. Il contesto efficace fornisce informazioni che il modello non potrebbe inferire autonomamente.
2.3 Struttura TCOF
| Punteggio | Descrizione |
|---|---|
| 1 | Un blocco di testo non strutturato |
| 3 | Alcune componenti presenti, ma manca l'organizzazione |
| 5 | Tutte e quattro le componenti TCOF chiaramente articolate: Task, Context, Output, Format |
Il framework TCOF (Task, Context, Output, Format) scompone il prompt in quattro componenti funzionali, ciascuna con un impatto distinto sulla qualità della risposta. L'articolo 1.5 di questo blog ne fornisce un'analisi completa con evidenze sperimentali.
Yin et al. [8] hanno condotto un'analisi sistematica della sensibilità dei modelli alle diverse componenti dell'istruzione, dimostrando che la rimozione delle specifiche sull'output produce il calo di performance più marcato. Il dato conferma che la strutturazione esplicita non è un formalismo ma un meccanismo che riduce l'entropia dell'output.

Figura 1. I sei criteri del modello Prompt Score. Ogni criterio valuta una dimensione indipendente della qualità del prompt, dal livello fondamentale (Chiarezza) a quello avanzato (Chain-of-Thought). I pesi riflettono l'impatto relativo sulla qualità della risposta generata.
2.4 Role Prompting
| Punteggio | Descrizione | Esempio |
|---|---|---|
| 1 | Nessun ruolo assegnato | "Analizza questi dati di vendita" |
| 3 | Ruolo generico | "Sei un esperto di business. Analizza questi dati di vendita" |
| 5 | Ruolo specifico con competenze e prospettiva | "Sei un data analyst senior specializzato in e-commerce B2C con 10 anni di esperienza nell'analisi delle performance stagionali. Analizza questi dati di vendita Q4 identificando pattern anomali rispetto ai benchmark del settore" |
Kong et al. [9], a NAACL 2024, hanno dimostrato che il role-play prompting migliora l'accuratezza su benchmark di ragionamento dal 53,5% al 63,8% (AQuA) e dal 23,8% all'84,2% (Last Letter). Il miglioramento non è marginale: è di un ordine di grandezza per alcuni task.
Il role prompting funziona perché modifica la distribuzione delle risposte del modello, attivando conoscenze e pattern linguistici associati al profilo specificato. Più il ruolo è specifico — con dominio, esperienza e prospettiva definiti — maggiore è l'effetto.
2.5 Few-Shot Examples
| Punteggio | Descrizione |
|---|---|
| 1 | Nessun esempio fornito |
| 3 | Un esempio presente, ma generico o non rappresentativo |
| 5 | 2-3 esempi specifici che mostrano chiaramente input atteso e output desiderato |
Brown et al. [6] hanno dimostrato che il few-shot prompting — fornire esempi di input-output — è il meccanismo fondamentale dell'in-context learning. Il modello apprende il pattern dagli esempi senza aggiornamento dei parametri.
L'efficacia del few-shot dipende dalla qualità degli esempi più che dalla quantità. Wei et al. [10] hanno mostrato che per task di ragionamento, anche un singolo esempio con catena di ragionamento esplicita (chain-of-thought) supera le prestazioni di molti esempi senza ragionamento.
Quando è essenziale: task con formati di output non standard, classificazioni con categorie specifiche del dominio, trasformazioni testo-a-testo con regole implicite.
2.6 Chain-of-Thought
| Punteggio | Descrizione |
|---|---|
| 1 | Nessun incoraggiamento al ragionamento step-by-step |
| 3 | Indicazione generica ("ragiona passo per passo") |
| 5 | Struttura di ragionamento esplicita con passaggi definiti ("Prima analizza X, poi valuta Y, infine concludi Z") |
Kojima et al. [11] hanno dimostrato che l'aggiunta di "Let's think step by step" è sufficiente a portare l'accuratezza su MultiArith dal 17,7% al 78,7% in modalità zero-shot. Wei et al. [10] hanno poi formalizzato il chain-of-thought prompting, mostrando miglioramenti significativi su task aritmetici, di ragionamento simbolico e di senso comune.
Il chain-of-thought non è utile per tutti i prompt. È particolarmente efficace per: task che richiedono ragionamento multi-step, analisi comparative, risoluzione di problemi complessi, e task in cui il modello tende a "saltare" ai risultati senza mostrare il processo.
3. Il Modello di Ponderazione
3.1 Pesi relativi
Non tutti i criteri hanno lo stesso impatto sulla qualità della risposta. Il modello Prompt Score adotta una ponderazione basata sull'evidenza sperimentale:
| Criterio | Peso | Motivazione |
|---|---|---|
| Chiarezza e Specificità | 0.25 | Determinante primario della performance [4][5] |
| Contesto | 0.20 | Riduce l'entropia dell'interpretazione [6] |
| Struttura TCOF | 0.20 | Garantisce completezza strutturale [8] |
| Role Prompting | 0.15 | Efficace ma non sempre necessario [9] |
| Chain-of-Thought | 0.10 | Cruciale per task complessi, meno per task semplici [10][11] |
| Few-Shot Examples | 0.10 | Potente ma opzionale per molti task [6] |
Il punteggio complessivo è calcolato come media ponderata:
dove è il peso del criterio e è il punteggio assegnato (1-5). Il risultato è un valore in .
3.2 Interpretazione del punteggio
| Range | Interpretazione | Azione suggerita |
|---|---|---|
| 4.0 - 5.0 | Eccellente | Il prompt è ben strutturato. Eventuali miglioramenti sono marginali. |
| 3.0 - 3.9 | Buono | Solida base, ma alcune dimensioni sono sottosviluppate. |
| 2.0 - 2.9 | Da migliorare | Mancano elementi importanti. Seguire i suggerimenti per criterio. |
| 1.0 - 1.9 | Insufficiente | Ristrutturazione necessaria. Partire dalla chiarezza e dal contesto. |
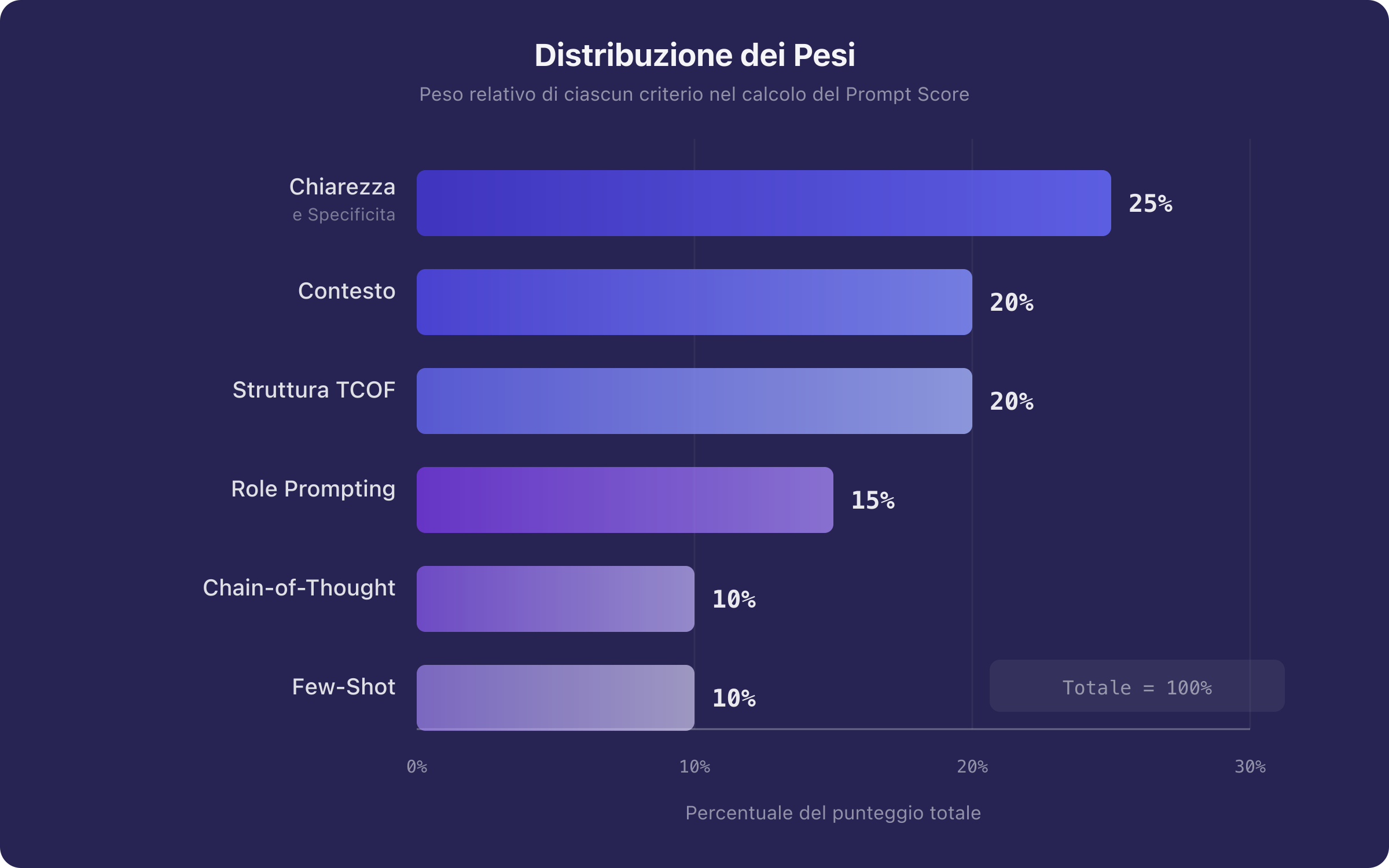
Figura 2. Distribuzione dei pesi nel modello Prompt Score. I pesi riflettono l'impatto relativo di ciascun criterio sulla qualità della risposta, basato sulle evidenze sperimentali della letteratura.
3.3 Perché la ponderazione non è uniforme
Una domanda legittima è: perché non assegnare lo stesso peso a tutti i criteri? La risposta sta nell'asimmetria degli impatti.
Un prompt con chiarezza 1/5 ma chain-of-thought 5/5 produrrà quasi certamente risultati scadenti: il modello ragionerà passo per passo, ma su un task mal definito. Viceversa, un prompt con chiarezza 5/5 e chain-of-thought 1/5 produrrà risultati buoni per task semplici e accettabili per task complessi.
La ponderazione cattura questa asimmetria: i criteri fondamentali (chiarezza, contesto, struttura) hanno pesi maggiori perché il loro impatto è universale. I criteri avanzati (role prompting, few-shot, chain-of-thought) hanno pesi minori perché il loro impatto è condizionale — dipende dal tipo di task.
4. Caso Studio: Dall'Analisi al Miglioramento
4.1 Il prompt iniziale
Consideriamo un prompt reale per la generazione di contenuti marketing:
Scrivi un post per LinkedIn sulla nostra nuova feature di AI. Deve essere coinvolgente e professionale.
Sottoponiamolo all'analisi Prompt Score:
| Criterio | Punteggio | Diagnosi |
|---|---|---|
| Chiarezza | 2/5 | "post per LinkedIn" è generico. Manca: lunghezza, tipo (testo, carosello), CTA desiderata |
| Contesto | 1/5 | Nessuna informazione sull'azienda, la feature, il target |
| Struttura TCOF | 2/5 | Task presente ma vago. Mancano C, O, F |
| Role Prompting | 1/5 | Nessun ruolo assegnato |
| Few-Shot | 1/5 | Nessun esempio di post precedenti |
| Chain-of-Thought | 1/5 | Nessuna struttura di ragionamento |
| Complessivo | 1.5/5 |
4.2 Miglioramento guidato dal punteggio
Seguendo le indicazioni dei criteri con punteggio più basso (contesto: 1/5, role: 1/5), il prompt viene riformulato:
[Ruolo] Sei un copywriter senior specializzato in comunicazione B2B SaaS su LinkedIn, con esperienza nella tech industry.
[Task] Scrivi un post LinkedIn per annunciare una nuova feature del nostro prodotto.
[Contesto] L'azienda è Keep My Prompts, una piattaforma per organizzare e ottimizzare prompt AI. La nuova feature è il "Prompt Score System": un sistema di valutazione automatica che analizza i prompt su 6 criteri e assegna un punteggio da 1 a 5. Il target sono professionisti che usano ChatGPT, Claude o Gemini quotidianamente per lavoro.
[Output] Il post deve: catturare l'attenzione nelle prime 2 righe (hook), spiegare il beneficio in 3-4 righe, includere un esempio concreto, concludere con una CTA chiara. Tono: professionale ma accessibile, con un tocco di entusiasmo. Lunghezza: 150-200 parole.
[Formato] Usa paragrafi brevi (1-2 frasi ciascuno). Includi 2-3 emoji strategici. Aggiungi 3-5 hashtag rilevanti alla fine.
Nuova analisi:
| Criterio | Prima | Dopo | Variazione |
|---|---|---|---|
| Chiarezza | 2/5 | 5/5 | +3 |
| Contesto | 1/5 | 5/5 | +4 |
| Struttura TCOF | 2/5 | 5/5 | +3 |
| Role Prompting | 1/5 | 5/5 | +4 |
| Few-Shot | 1/5 | 1/5 | 0 |
| Chain-of-Thought | 1/5 | 1/5 | 0 |
| Complessivo | 1.5/5 | 3.9/5 | +2.4 |
Il punteggio complessivo è passato da 1.5 a 3.9, un miglioramento del 160%. I due criteri rimasti a 1/5 (few-shot e chain-of-thought) non sono necessariamente un problema: per un post LinkedIn, gli esempi sono utili ma non essenziali, e il chain-of-thought non è richiesto per la generazione di testo creativo.
4.3 La lezione
Il valore del sistema di scoring non sta nel punteggio assoluto, ma nella diagnostica. Il prompt iniziale aveva punteggio 1.5 non perché fosse "sbagliato", ma perché mancava di informazioni che il modello non poteva inferire autonomamente. Il sistema di scoring ha identificato esattamente quali dimensioni mancavano (contesto, role), permettendo un miglioramento mirato.
5. Punteggio e Iterazione: Il Ciclo di Miglioramento
5.1 Il prompt come artefatto iterativo
Un errore comune è trattare il prompt come un artefatto statico: lo si scrive una volta e lo si usa ripetutamente. In realtà, i prompt più efficaci sono il risultato di iterazioni successive, ciascuna informata dal feedback della risposta e — con un sistema di scoring — dal feedback strutturale.
Il ciclo di miglioramento ideale è:
- Scrivi il prompt iniziale
- Valuta con il sistema di scoring
- Identifica i criteri con punteggio più basso
- Migliora quei criteri specifici
- Rivaluta e confronta con la versione precedente
- Salva la versione con il punteggio come snapshot
5.2 Il valore del tracciamento storico
Quando il punteggio viene salvato insieme a ogni versione del prompt, emerge un pattern potente: si può vedere l'evoluzione della qualità nel tempo. Un prompt che parte da 2.1 e dopo tre iterazioni raggiunge 4.2 racconta una storia di miglioramento misurabile.
Questo approccio è particolarmente prezioso nei team, dove diversi membri possono contribuire al miglioramento dei prompt. Il punteggio funge da lingua franca: "il prompt è passato da 2.3 a 4.1" è un'informazione oggettiva, non un giudizio soggettivo.
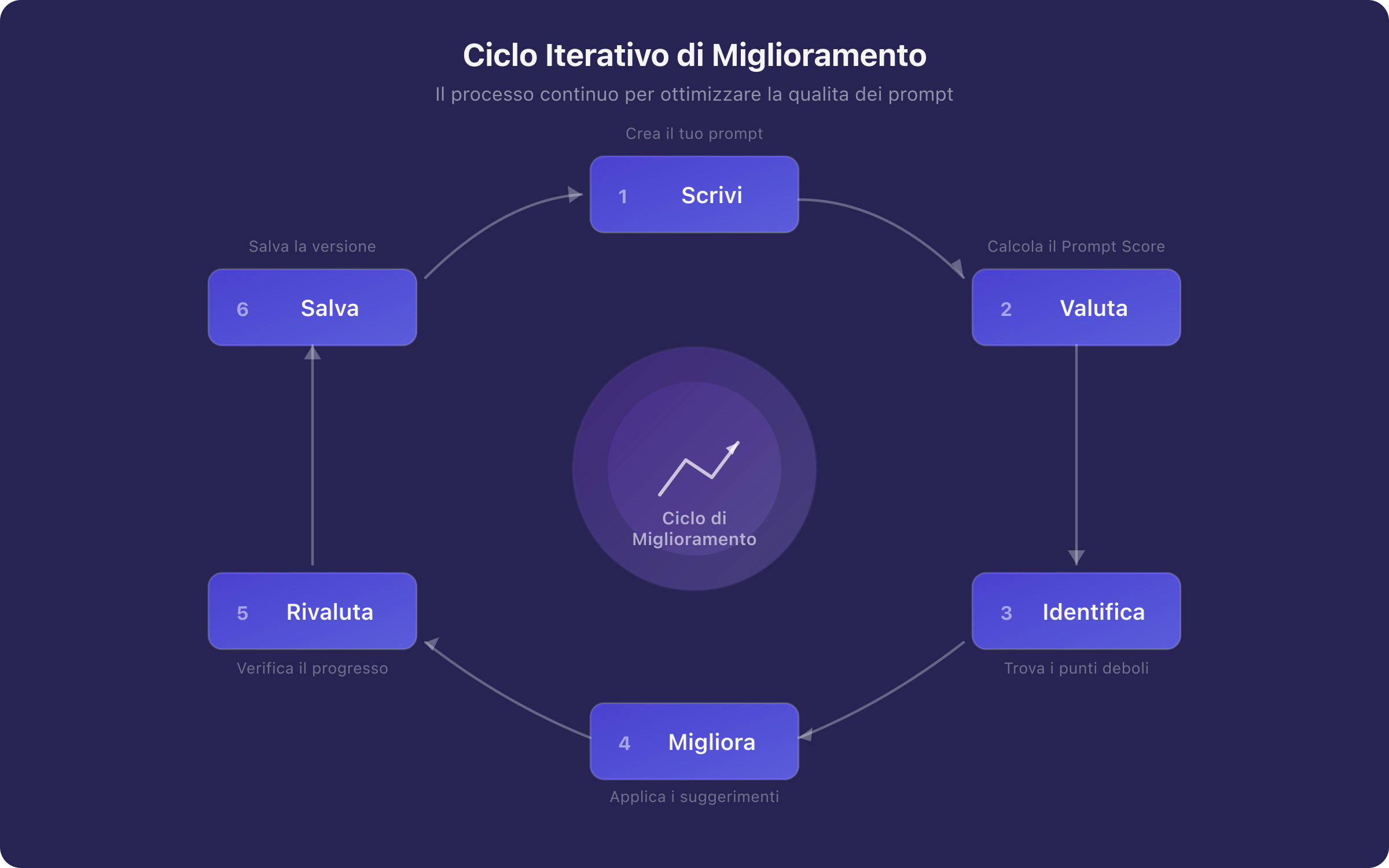
Figura 3. Il ciclo iterativo di miglioramento del prompt guidato dal Prompt Score. Ogni iterazione è informata dalla diagnostica per criterio, permettendo miglioramenti mirati. Il tracciamento storico delle versioni con snapshot del punteggio rende visibile l'evoluzione della qualità.
6. Limitazioni e Avvertenze
6.1 Cosa il punteggio non misura
Il sistema di scoring valuta le proprietà strutturali del prompt, non la sua efficacia per un task specifico. Un prompt con punteggio 5/5 su tutti i criteri potrebbe comunque produrre risultati mediocri se:
- Il task è intrinsecamente oltre le capacità del modello
- Il dominio è fuori dalla distribuzione dei dati di addestramento
- Le istruzioni sono internamente contraddittorie (il punteggio rileva la struttura, non la coerenza semantica)
6.2 Il punteggio non è assoluto
Un prompt con punteggio 2.5 non è necessariamente "peggiore" di uno con 4.0 in senso operativo. Il contesto d'uso conta: un prompt rapido per brainstorming non ha bisogno della stessa strutturazione di un prompt per la generazione di report. Il punteggio indica il grado di strutturazione, non il valore intrinseco.
6.3 Il rischio dell'over-engineering
Esiste un punto di rendimenti decrescenti: aggiungere contesto, esempi e struttura oltre un certo livello non migliora più la risposta e può addirittura confondere il modello. Liu et al. [12] hanno documentato il fenomeno "lost in the middle": le informazioni posizionate nella parte centrale di un prompt lungo vengono utilizzate meno efficacemente. La qualità del contesto è più importante della quantità.
7. Strumenti per la Valutazione dei Prompt
7.1 Valutazione manuale
La valutazione manuale è possibile e formativa: si prende il prompt, si assegna un punteggio da 1 a 5 per ciascun criterio, si calcola la media ponderata. Il processo richiede 2-3 minuti ma sviluppa un'intuizione strutturata per la qualità dei prompt.
7.2 Valutazione automatica
Per chi gestisce molti prompt o vuole un feedback immediato, la valutazione automatica è la scelta naturale. Il Prompt Score System di Keep My Prompts implementa il modello descritto in questo articolo:
- Valutazione su 6 criteri con punteggio 1-5 ciascuno
- Punteggio complessivo ponderato con formula
- V-Meter visuale con codifica colore (rosso → verde) per feedback immediato
- Suggerimenti mirati: un consiglio operativo per migliorare l'area più debole
- Snapshot nelle versioni: il punteggio viene salvato con ogni versione del prompt, creando un tracciamento storico della qualità
- Valutazione automatica al salvataggio: ogni volta che salvi un prompt, il punteggio viene ricalcolato
Il vantaggio della valutazione automatica non è solo la velocità: è la consistenza. Un valutatore umano può essere influenzato dalla familiarità con il prompt, dal contesto del momento, dalla stanchezza. Il sistema automatico applica gli stessi criteri, con gli stessi pesi, ogni volta.
Conclusione
La valutazione quantitativa dei prompt non è un esercizio accademico: è uno strumento operativo che trasforma un processo intuitivo in un processo strutturato. I sei criteri del modello Prompt Score — chiarezza, contesto, struttura TCOF, role prompting, few-shot, chain-of-thought — catturano le dimensioni fondamentali della qualità del prompt, ciascuna supportata da evidenze sperimentali della letteratura.
Il messaggio principale di questo articolo non è "usa il sistema di scoring", ma "inizia a pensare ai prompt come artefatti misurabili". Che si usi un sistema automatico o una valutazione manuale, la semplice azione di porsi la domanda "quanto è chiaro questo prompt?" o "ho fornito contesto sufficiente?" migliora sistematicamente la qualità dell'output.
I prompt migliori non nascono per ispirazione. Nascono per iterazione informata.
Riferimenti
[1] Anthropic, "Prompt Engineering Guide," Claude Documentation, 2024.
[2] E. Schulhoff et al., "The Prompt Report: A Systematic Survey of Prompting Techniques," arXiv:2406.06608, 2024.
[3] S. M. Bsharat et al., "Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4," arXiv:2312.16171, 2023.
[4] Y. Zhou et al., "Large Language Models Are Human-Level Prompt Engineers," ICLR, 2023.
[5] S. Mishra et al., "Reframing Instructional Prompts to GPTk's Language," Findings of ACL, 2022.
[6] T. B. Brown et al., "Language Models are Few-Shot Learners," NeurIPS, 2020.
[7] C. Zheng et al., "Is 'A Helpful Assistant' the Best Role for LLMs? A Systematic Evaluation of LLM Role-Playing," Findings of EMNLP, 2024.
[8] F. Yin et al., "Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning," ACL, 2023.
[9] X. Kong et al., "Better Zero-Shot Reasoning with Role-Play Prompting," NAACL, 2024.
[10] J. Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," NeurIPS, 2022.
[11] T. Kojima et al., "Large Language Models are Zero-Shot Reasoners," NeurIPS, 2022.
[12] N. F. Liu et al., "Lost in the Middle: How Language Models Use Long Contexts," Transactions of the ACL, 2024.