Introduction
The prompt engineering literature has grown rapidly in recent years, producing a substantial repertoire of techniques — from few-shot prompting [1] to chain-of-thought reasoning [2], from role-play prompting [3] to decomposed prompting [4] — each supported by experimental evidence. Yet the majority of these techniques share an implicit prerequisite: the prompt on which they are applied must possess an adequate base structure. In the absence of such structure, even the most sophisticated techniques yield suboptimal results.
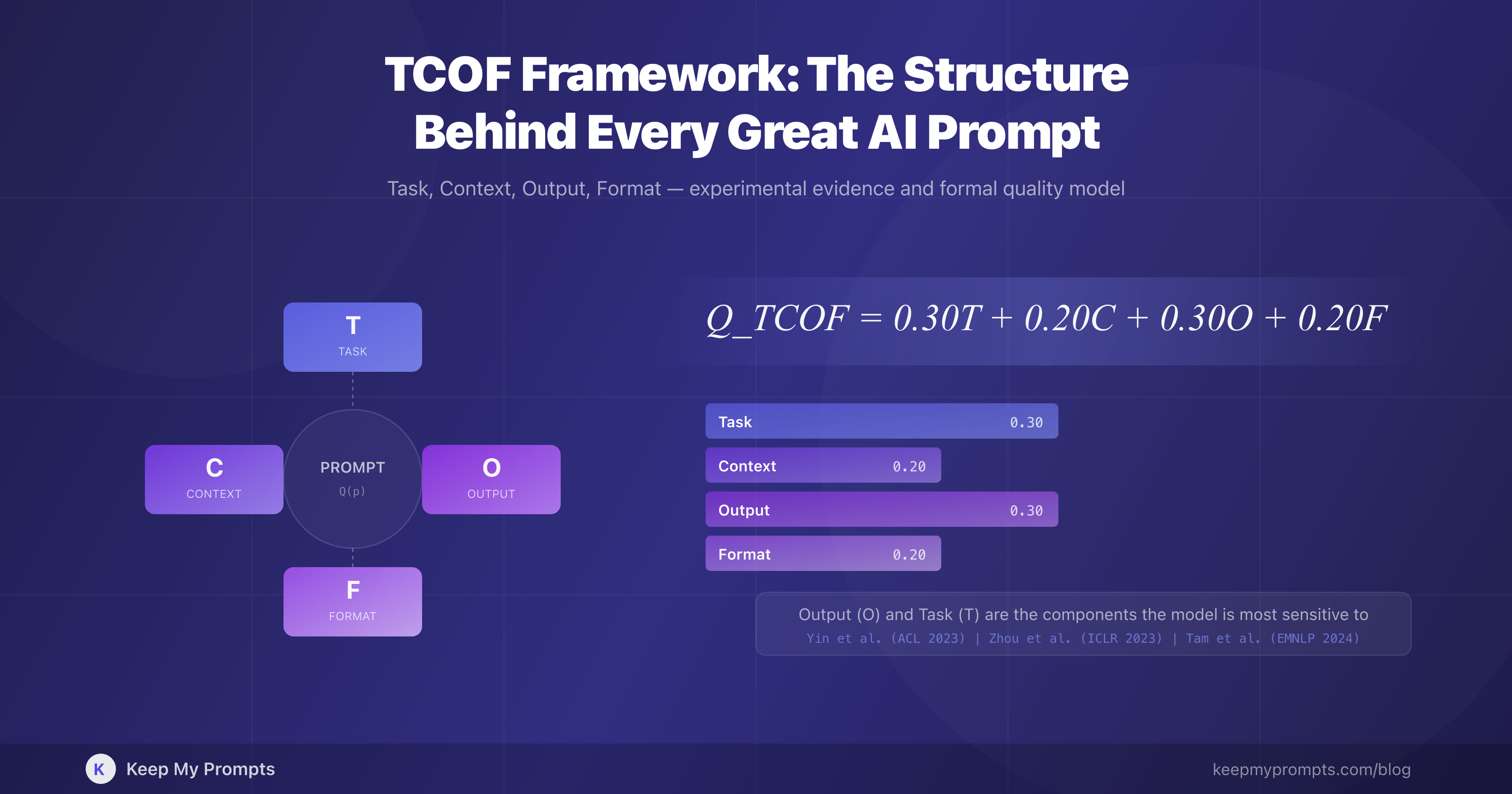
The present article formalizes this base structure through the TCOF framework (Task, Context, Output, Format), a four-component model that decomposes the prompt into discrete elements, each with a specific function and a measurable impact on the quality of the language model's response.
The TCOF framework is not an isolated invention but an operational synthesis of principles extensively documented in the research literature. Schulhoff et al. [5], in the most comprehensive systematic survey of prompt engineering to date (4,247 records analyzed, 58 techniques cataloged), identified prompt structuring as a cross-cutting theme across all taxonomic categories. Anthropic, in the official Claude documentation, explicitly recommends dividing prompts into labeled sections — instruction, context, input_data, output_format — effectively aligning with the TCOF logic [6].
The article is organized as follows: Section 1 presents the framework and its four components; Section 2 examines the experimental evidence for each component; Section 3 proposes a formal quality model based on TCOF; Section 4 discusses inter-component interactions; Section 5 addresses operational application; Section 6 covers the systematic management of structured prompts.
1. The TCOF Framework: Anatomy of a Structured Prompt
1.1 Definition
The TCOF framework decomposes a prompt into four functional components:
| Component | Symbol | Function | Guiding Question |
|---|---|---|---|
| Task | Defines the action required of the model | What should the model do? | |
| Context | Provides the background information necessary for execution | What information is needed to perform the task? | |
| Output | Specifies the expected characteristics of the response | What should the response look like? | |
| Format | Defines the structure and layout of the output | In what format should it be presented? |
The decomposition is not arbitrary. Each component acts on a distinct aspect of the model's generative process: defines the probability distribution over actions, conditions the distribution over the space of relevant knowledge, constrains the semantic properties of the response, and determines its syntactic structure.
1.2 A Complete Example
Consider the following unstructured request:
Tell me about digital marketing for SMEs.
Applying the TCOF framework, the same request becomes:
[T] Develop a digital marketing plan for the first 90 days following the launch of a new product.
[C] The company is an Italian SME in the organic food sector, with 12 employees and a monthly marketing budget of €5,000. The primary target audience is health-conscious consumers, aged 25–45, in metropolitan areas. The company has never invested in digital marketing before.
[O] The plan must include: measurable objectives (KPIs), recommended channels with rationale, a weekly activity timeline, budget allocation per channel, and evaluation metrics at 30-60-90 days.
[F] Organize the response in numbered sections with subheadings. For the timeline, use a table with columns: Week, Channel, Activity, Budget, KPI. Maximum length: 1,500 words.
The difference between the two prompts is not stylistic — it is structural. The first delegates every decision to the model: what to cover, at what depth, for what context, in what format. The second constrains the space of possible responses along four orthogonal dimensions, reducing output entropy and increasing the probability of obtaining a usable response on the first attempt.
1.3 TCOF in the Prompt Engineering Taxonomy
The TCOF framework occupies the foundational level of the prompt engineering taxonomy: it is the structure upon which advanced techniques are applied. In the classification proposed by Schulhoff et al. [5], TCOF falls within the "prompt engineering" category in the strict sense, distinct from "answer engineering" and "thought generation" techniques. In architectural terms, it constitutes the foundation — necessary but not sufficient.
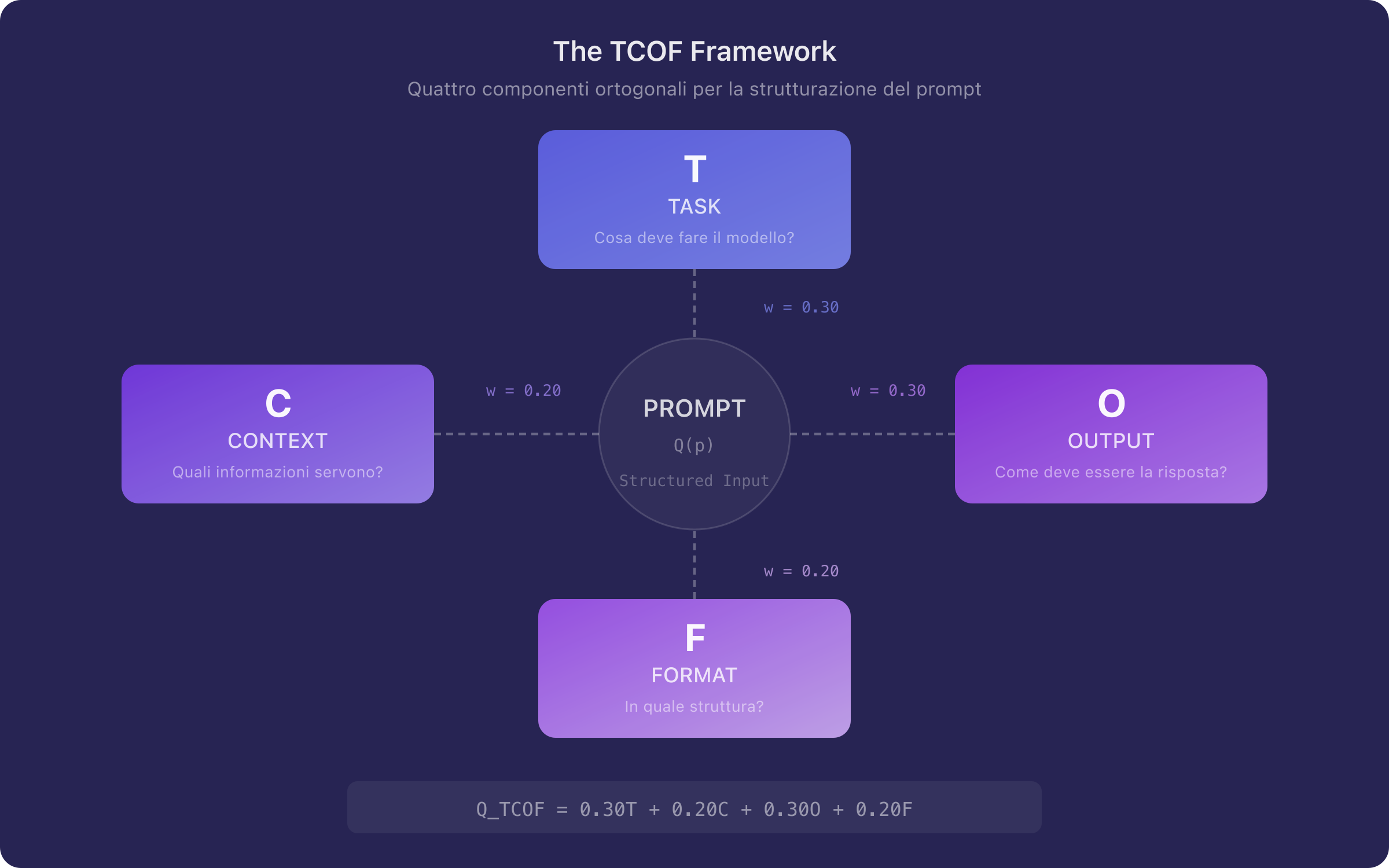
Figure 1. Schematic representation of the TCOF framework. The four components — Task, Context, Output, Format — operate on orthogonal dimensions of the prompt space, each reducing the entropy of the generated output along a specific axis.
2. Experimental Evidence by Component
2.1 Task (): The Dominant Component
The literature is unanimous in identifying the task specification as the most critical element of a prompt. Zhou et al. [7], in a study presented at ICLR 2023, demonstrated that automatic optimization of the instruction (the component) produces prompts that match or surpass those written by human experts on 21 out of 24 tasks. The finding is significant: it indicates that the quality of the task formulation is the primary determinant of performance, regardless of domain.
Mishra et al. [8], in a contribution to the Findings of ACL 2022, showed that structured reformulation of instructions — decomposing the task into sequential sub-tasks and specifying the action with precise verbs — improves GPT-3 performance by 12.5% on average across 12 diverse tasks. The technique, termed "reframing," is effectively a refinement operation on the component.
Bsharat et al. [9] systematized 26 principles for effective prompting, many of which directly concern task formulation: use explicit action verbs, avoid negations, specify the expected level of detail. Tests conducted on LLaMA and GPT-3.5/4 confirm consistent improvements.
Kojima et al. [10] demonstrated, at NeurIPS 2022, that a single phrase added to the task formulation — "Let's think step by step" — is sufficient to raise accuracy on MultiArith from 17.7% to 78.7% in zero-shot mode. The finding illustrates a fundamental point: even a minimal addition to the component, if structurally meaningful, can produce performance gains of an order of magnitude.
2.2 Context (): The Entropy Reducer
Context operates as conditioning information that narrows the space of possible interpretations. Brown et al. [1], in the foundational GPT-3 paper presented at NeurIPS 2020, established that the quantity and quality of contextual information provided in the prompt directly determine model performance — a principle they termed "in-context learning."
Kong et al. [3], at NAACL 2024, demonstrated that role-play prompting — a form of contextualization in which a specific identity is assigned to the model — improves accuracy on reasoning benchmarks from 53.5% to 63.8% (AQuA) and from 23.8% to 84.2% (Last Letter). Role-play systematically outperforms standard zero-shot, confirming that context provided through role assignment is not a rhetorical device but a mechanism that modifies the response distribution.
A qualification is necessary, however. Zheng et al. [11], in a study presented at the Findings of EMNLP 2024, showed that generic personas in system prompts (e.g., "you are a helpful assistant") do not improve performance on factual tasks. The result does not contradict the value of context but clarifies its nature: the component must provide specific, task-relevant information, not generic labels. It is the specificity of context that determines its effectiveness.
Liu et al. [12], in an analysis published in Transactions of the ACL, documented the "lost in the middle" phenomenon: information positioned in the central portion of a long context is utilized less effectively by the model than information placed at the beginning or end. The finding has direct implications for prompt structuring: positioning critical context at the beginning (immediately after the task) or at the end improves performance.
2.3 Output (): The Most Sensitive Component
Yin et al. [13], in a contribution presented at ACL 2023, conducted a systematic analysis of model sensitivity to different instruction components. The principal finding is that removing output specifications — particularly labels and descriptions of the expected response format — produces the most pronounced performance drop. Furthermore, an automatic compression algorithm demonstrated that 60% of an instruction's tokens can be removed without performance degradation, provided that output specifications are preserved.
The finding is notable and sometimes counterintuitive: the component is the one to which the model is most sensitive. A prompt with a vague task but clear output specifications can produce better results than a prompt with a detailed task but no indication of the expected output. In formal terms:
where represents response quality and the partial derivatives indicate sensitivity with respect to each component. The ordering is approximate and task-dependent, but the primacy of the component is robust across the analyzed benchmarks.
Nori et al. [14], in a Microsoft Research study, demonstrated that the Medprompt method — based on structured specification of the expected process and output — enabled GPT-4 to outperform specialist models such as Med-PaLM 2 with a 27% error reduction on MedQA, surpassing 90% accuracy for the first time. The results generalized to electrical engineering, machine learning, philosophy, accounting, law, and clinical psychology.
2.4 Format (): Structure with Caution
The format specification is the component requiring the most delicate balancing. On one hand, indicating the desired format (table, list, paragraph, JSON) reduces ambiguity and increases output usability. Wei et al. [2] demonstrated that requesting structured intermediate steps (chain-of-thought) — which is effectively a format specification for the reasoning process — significantly improves performance on reasoning tasks.
On the other hand, Tam et al. [15], in a study presented at EMNLP 2024, documented that imposing overly rigid format constraints (e.g., strict JSON schemas) degrades the model's reasoning capabilities. The finding suggests that the component should guide the output structure without mechanically constraining it.
The operational recommendation is therefore as follows: specify format in terms of logical structure (sections, tables, lists) rather than strict syntax (rigid JSON schemas with mandatory fields), unless the use case explicitly requires it.
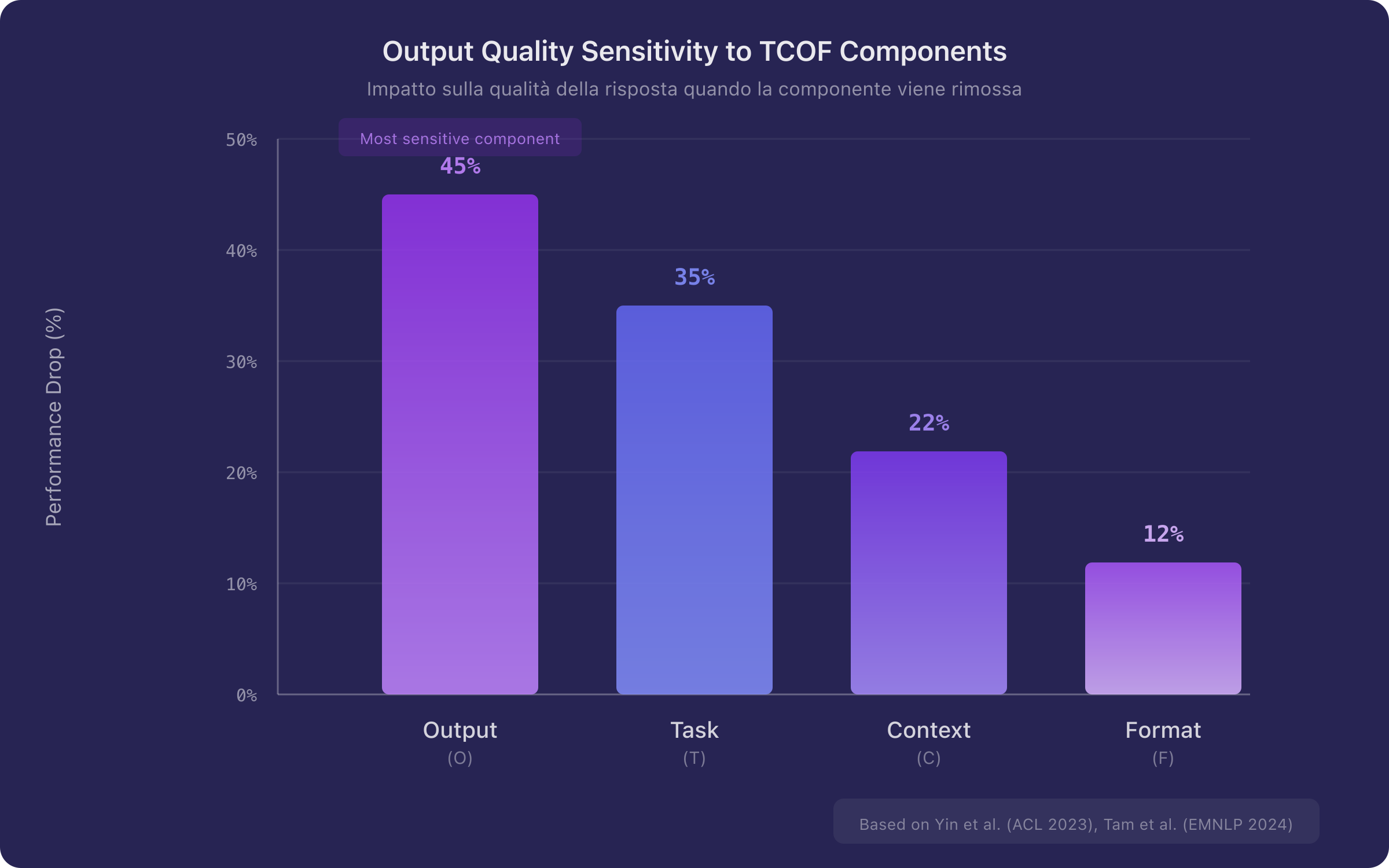
Figure 2. Qualitative representation of output quality sensitivity to the four TCOF components. The Output (O) component shows the highest sensitivity, followed by Task (T), Context (C), and Format (F). The ordering is based on data from Yin et al. [13] and Tam et al. [15].
3. A Formal Quality Model Based on TCOF
3.1 Model Definition
Based on the evidence presented in Section 2, a prompt quality model is proposed, defined as a weighted sum of the four components:
where represents the score of the -th component and the associated weight, subject to the constraint .
3.2 Weight Calibration
The weights are derived from experimental evidence according to the following rationale:
| Component | Weight | Justification |
|---|---|---|
| Task () | 0.30 | Necessary condition for generation [7][8][10] |
| Context () | 0.20 | Entropy reducer, moderate but consistent effect [1][3][12] |
| Output () | 0.30 | Highest model sensitivity [13][14] |
| Format () | 0.20 | Useful structure, but rigid constraints counterproductive [2][15] |
Note that, unlike the five-component model proposed in [16], the TCOF model assigns equal weight to Task and Output (0.30 each), reflecting the evidence from Yin et al. [13] on the critical sensitivity of the model to output specifications. Context and Format each receive a weight of 0.20.
3.3 Quality Threshold
A minimum quality threshold is defined based on the evidence that the presence of at least three out of four components is sufficient to produce a usable output in the majority of cases. If each present component receives a conservative score of (out of 5):
where is the average weight of the three highest-scoring components. In practice, a prompt with at least three well-formulated TCOF components produces appreciably better results than an unstructured prompt.

Figure 3. Weight distribution in the model. Task and Output share the highest weight (30% each), reflecting their dominant impact on response quality. Context and Format each contribute 20%.
4. Inter-Component Interactions
4.1 Synergies
The four TCOF components do not operate independently. Significant synergistic interactions are observed:
T × C (Task × Context): a precise task amplifies the effect of context. The context "organic food sector, Italian SME, 12 employees" is useful only if the task activates it ("develop a marketing plan"); otherwise, it remains inert information. Zamfirescu-Pereira et al. [17] documented how non-expert users tend to provide context without a clear task, obtaining informative but non-actionable responses.
O × F (Output × Format): output and format specifications are complementary. The request "include measurable KPIs" () and the request "organize in a table" () jointly produce a more usable result than either specification alone.
T × O (Task × Output): this is the most critical interaction. As highlighted by Yin et al. [13], the combination of a clear task with precise output specifications produces the maximum quality gain. In formal terms, this is a super-additive interaction:
4.2 Conflicts
Not all interactions are positive. Tam et al. [15] documented the conflict in reasoning tasks: a task requiring complex reasoning combined with a rigid format (JSON with a fixed schema) produces inferior performance compared to the same task without format constraints. The recommendation is to relax format constraints when the task requires multi-step reasoning.
4.3 Positional Ordering
Liu et al. [12] demonstrated that the position of information within the prompt affects how effectively the model utilizes it. The TCOF acronym reflects an optimal positional ordering:
- Task at the opening — the primary instruction is the element that orients the entire generation
- Context immediately after — background information conditions the interpretation of the task
- Output in the mid-to-late position — output specifications guide the generative phase
- Format at the close — structural constraints are applied during final formatting
This ordering is not a rigid requirement, but it reflects the principle documented in [12]: information at the beginning and end of the prompt receives greater attention, while information in the middle tends to be underutilized.
5. Operational Application
5.1 TCOF Protocol in Four Phases
An operational protocol for the systematic application of the framework is proposed:
Phase 1 — Task: formulate the primary instruction using a specific action verb. Avoid vague verbs ("tell me about," "help me with") in favor of precise ones ("analyze," "compare," "develop," "synthesize," "evaluate").
Phase 2 — Context: identify the necessary background information by answering: Who is the audience? What is the domain? What external constraints exist? What prior knowledge is required?
Phase 3 — Output: specify the expected characteristics of the response: what it must include, what level of detail, what quality criteria. This is the phase deserving the greatest attention, based on the evidence from Yin et al. [13].
Phase 4 — Format: indicate the desired structure (sections, tables, lists) and length constraints. Avoid overly rigid format specifications for tasks requiring reasoning.
5.2 Applied Example: Three Levels of Structuring
The cumulative effect of progressively adding TCOF components is illustrated below:
Task only ():
Analyze this quarter's sales performance.
Task + Context ():
Analyze the Q3 2025 sales performance for a sportswear e-commerce company with €2M annual revenue. The previous quarter registered a 12% decline compared to Q2.
Complete TCOF ():
[T] Analyze the Q3 2025 sales performance and identify the primary causes of variation compared to the previous quarter.
[C] The company is a sportswear e-commerce business with €2M annual revenue. Q2 2025 registered a 12% decline compared to Q1, attributed to reduced organic traffic and supply chain issues on the running line.
[O] The analysis must include: (1) quantitative Q3 vs Q2 comparison for the top 5 product categories; (2) identification of the 3 primary factors explaining the variation; (3) assessment of each factor's impact; (4) operational recommendations for Q4 with estimated impact.
[F] Structure the response in 4 numbered sections. For the category comparison, use a table. For recommendations, use a numbered list with priority levels (high/medium/low). Length: 800–1,000 words.
The progression illustrates how each additional component reduces the space of possible responses and increases the probability of obtaining a directly usable output.
5.3 Anti-Patterns: Common Application Errors
Application of the TCOF framework is not immune to errors. The following table classifies the most frequent ones:
| Anti-pattern | Component | Description | Example |
|---|---|---|---|
| Implicit task | The required action is not stated explicitly | "Digital marketing for SMEs" (not a task) | |
| Generic context | Background information too vague to be useful | "An Italian company" (which sector? size? market?) | |
| Non-verifiable output | Specifications do not allow response evaluation | "Give me a good analysis" (what makes it "good"?) | |
| Over-specified format | Structural constraints so rigid they constrain reasoning | "Respond ONLY in JSON with exactly 7 fields" for an analytical task | |
| Positional inversion | Context precedes the task, diluting its effect | Two paragraphs of background before the actual request |
6. Systematic Management of TCOF Prompts
6.1 From Individual Prompts to a Structured Library
The systematic application of the TCOF framework to a growing number of tasks produces a desirable side effect: prompts become modular and reusable. A prompt structured according to TCOF naturally lends itself to categorization (by task type), tagging (by context domain), and versioning (modifications typically affect only one component per iteration).
Liu et al. [18], in a survey published in ACM Computing Surveys, highlighted that prompting has become a central paradigm in language model interaction, and that effective prompt management represents a critical factor for productivity. The challenge is not writing a single good prompt but building and maintaining a library of structured prompts that evolves over time.
6.2 Versioning and Quality
The TCOF framework facilitates iterative refinement because it makes the dimensions of improvement explicit. When a prompt fails to produce the desired output, diagnosis can be conducted component by component:
- If the output is off-topic → problem in the component
- If the output is generic → problem in the component
- If the output is incomplete or superficial → problem in the component
- If the output is unstructured or illegible → problem in the component
This diagnostic property makes TCOF particularly well-suited to management systems that support versioning: each prompt version can be annotated with the modified component and the rationale for the change.
6.3 Automated Quality Assessment
The model lends itself to implementation in automated prompt quality assessment systems. A system that analyzes the presence and quality of the four components can provide an objective score and targeted improvement suggestions.
The Keep My Prompts platform implements a Prompt Score system based on criteria analogous to those of the TCOF framework: clarity and specificity (mapping to the component), context (), TCOF structure (), role prompting (an extension of ), few-shot examples, and chain-of-thought (complementary techniques). The score is calculated automatically on a 1–5 scale with differentiated weights, providing both a synthetic indicator and operational suggestions for improvement. For teams, collaborative plans are available that enable sharing structured prompts with per-author version tracking.
7. TCOF and Advanced Techniques: A Complementary Relationship
7.1 TCOF as a Prerequisite
The TCOF framework does not replace advanced prompting techniques — it enables them. Consider the relationship between TCOF and three fundamental techniques:
Chain-of-Thought [2]: CoT is a technique that operates on the component, specifying that the output must include intermediate reasoning steps. Without a clearly defined task (), step-by-step reasoning has no objective toward which to converge.
Few-Shot [1]: examples provided in the prompt are an extension of the component, illustrating the expected pattern through input-output pairs. Without output specifications (), examples may be interpreted ambiguously by the model.
Decomposed Prompting [4]: Khot et al. demonstrated that decomposing complex tasks into simpler sub-tasks improves performance. Decomposition operates on the component but requires that output specifications () be defined for each sub-task.
7.2 Compatibility Schema
| Advanced Technique | TCOF Component Affected | TCOF Prerequisite |
|---|---|---|
| Chain-of-Thought | (output process) | Clear |
| Few-Shot | (examples as context) | Defined |
| Role Prompting | (persona as context) | Specific |
| Decomposed Prompting | (task decomposition) | for each sub-task |
| Self-Consistency | (aggregation format) | Complete |
8. Conclusions
8.1 Summary
The present article has proposed the TCOF framework (Task, Context, Output, Format) as a foundational structure for constructing effective prompts. Experimental evidence drawn from contributions presented at NeurIPS [2][10], ICLR [7], ACL [8][13], NAACL [3], EMNLP [11][15], and others converges on three principal conclusions:
-
Prompt structure is the primary determinant of output quality. Not length, not lexical sophistication, but the presence of discrete, well-defined functional components.
-
The Output () component is the one to which the model is most sensitive, followed by Task (). Sixty percent of an instruction's tokens can be removed without degradation, provided that output specifications are preserved [13].
-
The TCOF framework is complementary to, not a substitute for, advanced techniques. Chain-of-thought, few-shot, and decomposed prompting produce their best results when applied to prompts already structured according to TCOF.
8.2 Operational Recommendation
Based on the analysis conducted, the following recommendation is offered: before submitting any prompt to a language model, verify that it contains at least the Task and Output components of the TCOF framework. These two components, which share the highest weight in the model (0.30 each, totaling 60%), represent the minimum threshold for obtaining usable results on the first attempt.
The progressive addition of Context and Format further elevates quality, but the most favorable cost-benefit ratio is achieved by ensuring the presence of the first two components.
References
[1] T. Brown et al., "Language Models are Few-Shot Learners," Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020. arXiv: 2005.14165.
[2] J. Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," Advances in Neural Information Processing Systems, vol. 35, 2022. arXiv: 2201.11903.
[3] A. Kong et al., "Better Zero-Shot Reasoning with Role-Play Prompting," Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024. arXiv: 2308.07702.
[4] T. Khot et al., "Decomposed Prompting: A Modular Approach for Solving Complex Tasks," Proceedings of the International Conference on Learning Representations (ICLR), 2023. arXiv: 2210.02406.
[5] S. Schulhoff et al., "The Prompt Report: A Systematic Survey of Prompt Engineering Techniques," arXiv preprint, 2024. arXiv: 2406.06608.
[6] Anthropic, "Use XML Tags to Structure Your Prompts," Claude Documentation, 2024. Available: https://docs.anthropic.com/en/build-with-claude/prompt-engineering/use-xml-tags
[7] Y. Zhou et al., "Large Language Models Are Human-Level Prompt Engineers," Proceedings of the International Conference on Learning Representations (ICLR), 2023. arXiv: 2211.01910.
[8] S. Mishra et al., "Reframing Instructional Prompts to GPTk's Language," Findings of the Association for Computational Linguistics: ACL 2022, pp. 589–612, 2022. arXiv: 2109.07830.
[9] S. M. Bsharat, A. Myrzakhan, Z. Shen, "Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4," arXiv preprint, 2024. arXiv: 2312.16171.
[10] T. Kojima et al., "Large Language Models are Zero-Shot Reasoners," Advances in Neural Information Processing Systems, vol. 35, 2022. arXiv: 2205.11916.
[11] M. Zheng et al., "When 'A Helpful Assistant' Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models," Findings of the Association for Computational Linguistics: EMNLP 2024, 2024. arXiv: 2311.10054.
[12] N. F. Liu et al., "Lost in the Middle: How Language Models Use Long Contexts," Transactions of the Association for Computational Linguistics, vol. 12, pp. 157–173, 2024. DOI: 10.1162/tacl_a_00638.
[13] F. Yin et al., "Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning," Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), Toronto, 2023. arXiv: 2306.01150.
[14] H. Nori et al., "Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine," arXiv preprint, 2023. arXiv: 2311.16452.
[15] Z. R. Tam et al., "Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models," EMNLP 2024 Industry Track, 2024. arXiv: 2408.02442.
[16] S. Petrucci, "How to Write Effective Prompts for ChatGPT: A Practical Guide with a Scientific Approach," Keep My Prompts Blog, 2025. Available: https://www.keepmyprompts.com/blog/en/how-to-write-effective-chatgpt-prompts
[17] J. D. Zamfirescu-Pereira et al., "Why Johnny Can't Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts," Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 2023. DOI: 10.1145/3544548.3581388.
[18] P. Liu et al., "Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing," ACM Computing Surveys, vol. 55, no. 9, pp. 1–35, 2023. DOI: 10.1145/3560815.