Introduzione
Nell'ambito dell'ingegneria dei prompt, la letteratura scientifica ha prodotto un vasto repertorio di tecniche — dal few-shot prompting [1] al chain-of-thought [2], dal role-play [3] alla decomposizione modulare [4] — ciascuna con evidenze sperimentali a supporto. Tuttavia, la maggior parte di queste tecniche condivide un presupposto implicito: il prompt su cui vengono applicate deve possedere una struttura di base adeguata. In assenza di tale struttura, anche le tecniche più sofisticate producono risultati subottimali.
Il presente articolo si propone di formalizzare questa struttura di base attraverso il framework TCOF (Task, Context, Output, Format), un modello a quattro componenti che scompone il prompt in elementi discreti, ciascuno con una funzione specifica e un impatto misurabile sulla qualità della risposta generata dal modello linguistico.
Il framework TCOF non è un'invenzione isolata, ma una sintesi operativa di principi ampiamente documentati nella ricerca. Schulhoff et al. [5], nella più estesa survey sistematica sul prompt engineering a oggi disponibile (4.247 record analizzati, 58 tecniche catalogate), hanno identificato la strutturazione del prompt come tema trasversale a tutte le categorie tassonomiche. Anthropic, nella documentazione ufficiale di Claude, raccomanda esplicitamente la suddivisione del prompt in sezioni etichettate — instruction, context, input_data, output_format — allineandosi di fatto alla logica TCOF [6].
L'articolo si articola come segue: nella Sezione 1 si presenta il framework con le sue quattro componenti; nella Sezione 2 si analizzano le evidenze sperimentali per ciascun componente; nella Sezione 3 si propone un modello formale di qualità del prompt basato su TCOF; nella Sezione 4 si discutono le interazioni tra componenti; nella Sezione 5 si affronta l'applicazione operativa; nella Sezione 6 si tratta la gestione sistematica dei prompt strutturati.
1. Il Framework TCOF: Anatomia di un Prompt Strutturato
1.1 Definizione
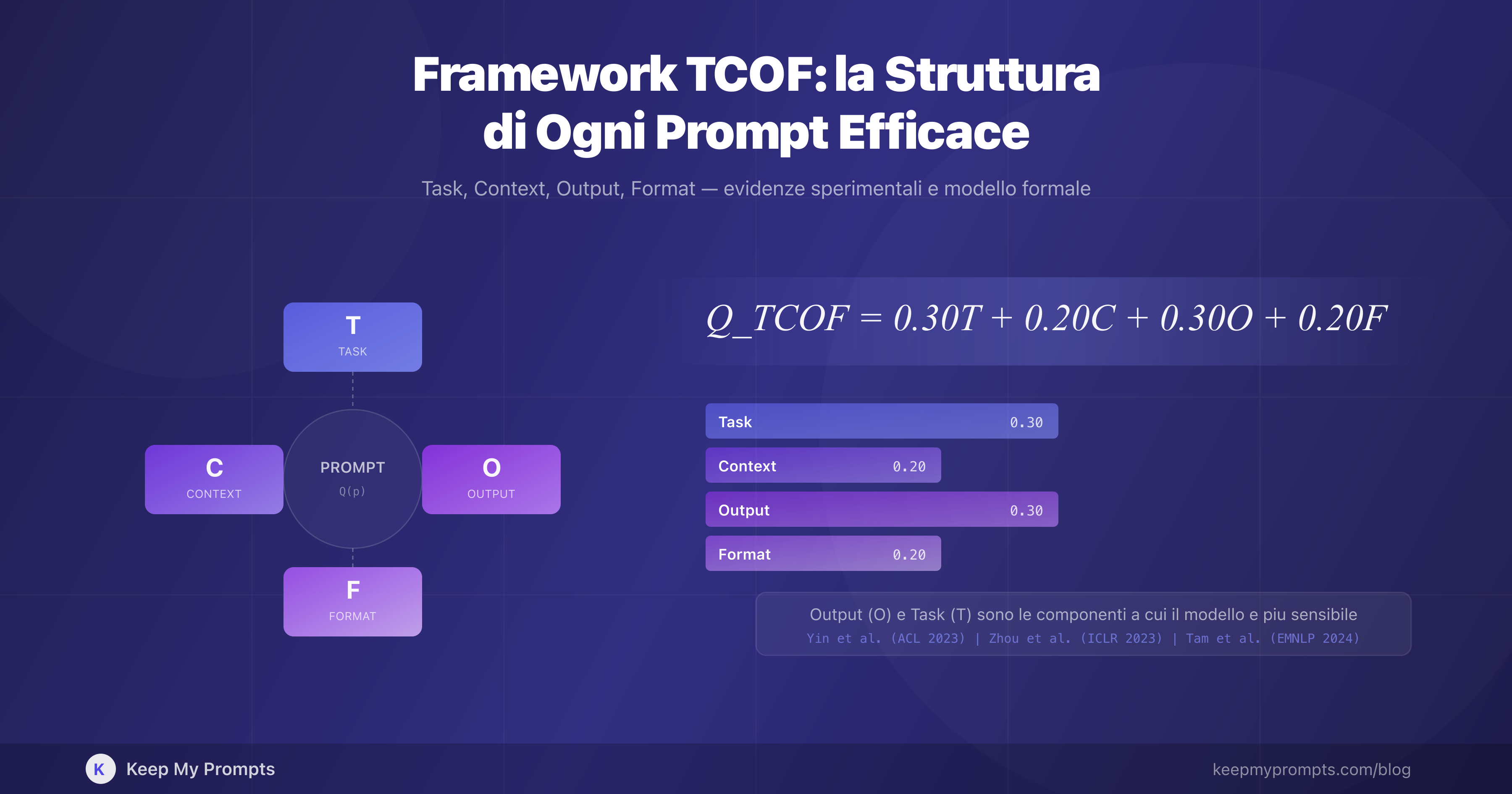
Il framework TCOF scompone un prompt in quattro componenti funzionali:
| Componente | Simbolo | Funzione | Domanda guida |
|---|---|---|---|
| Task | Definisce l'azione richiesta al modello | Cosa deve fare il modello? | |
| Context | Fornisce le informazioni di sfondo necessarie | Quali informazioni servono per eseguire il task? | |
| Output | Specifica le caratteristiche attese della risposta | Come deve essere la risposta? | |
| Format | Definisce la struttura e il layout dell'output | In quale formato deve essere presentata? |
La decomposizione non è arbitraria. Ciascuna componente agisce su un aspetto distinto del processo generativo del modello: definisce la distribuzione di probabilità sull'azione, condiziona la distribuzione sullo spazio delle conoscenze rilevanti, vincola le proprietà semantiche della risposta, e ne determina la struttura sintattica.
1.2 Un esempio completo
Si consideri la seguente richiesta non strutturata:
Parlami del marketing digitale per le PMI.
Applicando il framework TCOF, la stessa richiesta diventa:
[T] Elabora un piano di marketing digitale per i primi 90 giorni dal lancio di un nuovo prodotto.
[C] L'azienda è una PMI italiana del settore alimentare biologico, con 12 dipendenti e un budget marketing di 5.000 euro al mese. Il target primario sono consumatori attenti alla salute, 25-45 anni, area metropolitana. L'azienda non ha mai investito in marketing digitale.
[O] Il piano deve includere: obiettivi misurabili (KPI), canali consigliati con motivazione, timeline settimanale delle attività, allocazione del budget per canale, e metriche di valutazione a 30-60-90 giorni.
[F] Organizza la risposta in sezioni numerate con sottotitoli. Per la timeline usa una tabella con colonne: Settimana, Canale, Attività, Budget, KPI. Lunghezza massima: 1.500 parole.
La differenza tra i due prompt non è stilistica: è strutturale. Il primo delega al modello ogni decisione — cosa trattare, con quale profondità, per quale contesto, in quale formato. Il secondo vincola lo spazio delle risposte possibili lungo quattro dimensioni ortogonali, riducendo l'entropia dell'output e aumentando la probabilità di ottenere una risposta utilizzabile al primo tentativo.
1.3 TCOF nella tassonomia delle tecniche di prompting
Il framework TCOF si colloca al livello fondamentale della tassonomia del prompt engineering: è la struttura su cui le tecniche avanzate vengono applicate. Nella classificazione proposta da Schulhoff et al. [5], TCOF rientra nella categoria "prompt engineering" in senso stretto, distinguendosi dalle tecniche di "answer engineering" e "thought generation". Si tratta, in termini architetturali, delle fondamenta: necessarie ma non sufficienti.
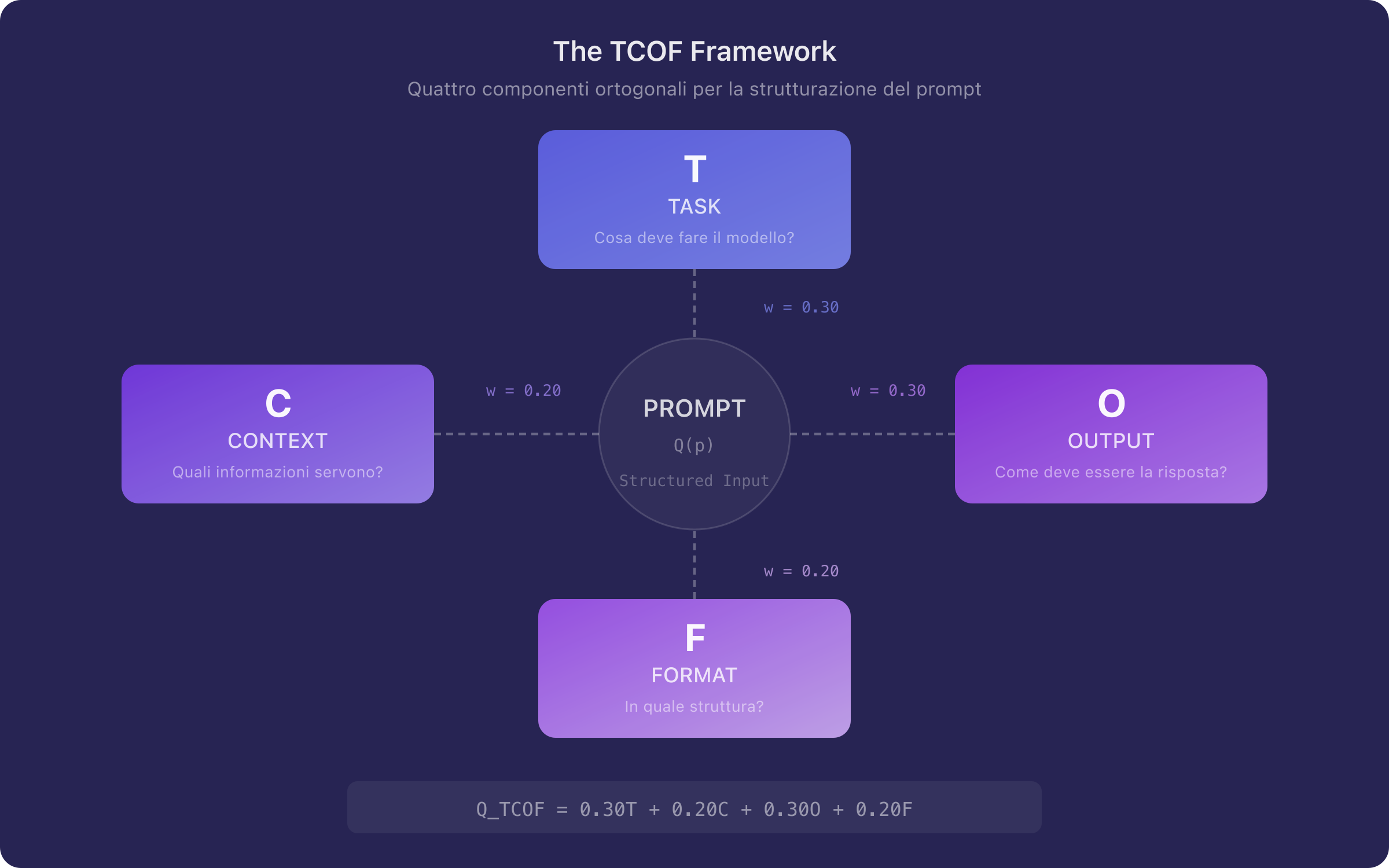
Figura 1. Rappresentazione schematica del framework TCOF. Le quattro componenti — Task, Context, Output, Format — operano su dimensioni ortogonali dello spazio del prompt, ciascuna riducendo l'entropia dell'output generato lungo un asse specifico.
2. Evidenze Sperimentali per Componente
2.1 Task (): la componente dominante
La letteratura è unanime nell'identificare la specifica del task come l'elemento più critico di un prompt. Zhou et al. [7], in uno studio presentato a ICLR 2023, hanno dimostrato che l'ottimizzazione automatica dell'istruzione (componente ) produce prompt che eguagliano o superano quelli scritti da esperti umani in 21 task su 24. Il dato è significativo: indica che la qualità della formulazione del task è il principale determinante della performance, indipendentemente dal dominio.
Mishra et al. [8], in un contributo ai Findings di ACL 2022, hanno mostrato che la riformulazione strutturata delle istruzioni — decomponendo il task in sotto-task sequenziali e specificando l'azione con verbi precisi — migliora le prestazioni di GPT-3 del 12,5% in media su 12 task diversi. La tecnica, denominata "reframing", è di fatto un'operazione di raffinamento della componente .
Bsharat et al. [9] hanno sistematizzato 26 principi per il prompting efficace, molti dei quali riguardano direttamente la formulazione del task: usare verbi d'azione espliciti, evitare negazioni, specificare il livello di dettaglio atteso. I test condotti su LLaMA e GPT-3.5/4 confermano miglioramenti consistenti.
Kojima et al. [10] hanno dimostrato, a NeurIPS 2022, che una singola frase aggiunta alla formulazione del task — "Let's think step by step" — è sufficiente a portare l'accuratezza su MultiArith dal 17,7% al 78,7% in modalità zero-shot. Il dato illustra un punto fondamentale: anche un'aggiunta minimale alla componente , se strutturalmente significativa, può produrre guadagni di performance di un ordine di grandezza.
2.2 Context (): il riduttore di entropia
Il contesto opera come informazione condizionante che restringe lo spazio delle interpretazioni possibili. Brown et al. [1], nel contributo fondamentale su GPT-3 presentato a NeurIPS 2020, hanno stabilito che la quantità e la qualità delle informazioni contestuali fornite nel prompt determinano in modo diretto la performance del modello — un principio che hanno denominato "in-context learning".
Kong et al. [3], a NAACL 2024, hanno dimostrato che il role-play prompting — una forma di contestualizzazione in cui si assegna un'identità specifica al modello — migliora l'accuratezza su benchmark di ragionamento dal 53,5% al 63,8% (AQuA) e dal 23,8% all'84,2% (Last Letter). Il role-play supera sistematicamente lo zero-shot standard, confermando che il contesto fornito attraverso il ruolo non è un artificio retorico ma un meccanismo che modifica la distribuzione delle risposte.
È tuttavia necessaria una precisazione. Zheng et al. [11], in uno studio presentato ai Findings di EMNLP 2024, hanno mostrato che le persona generiche nei system prompt (ad esempio "sei un assistente utile") non migliorano le prestazioni su task fattuali. Il risultato non contraddice il valore del contesto, ma ne precisa la natura: la componente deve fornire informazioni specifiche e rilevanti per il task, non etichette generiche. La specificità del contesto è ciò che ne determina l'efficacia.
Liu et al. [12], in un'analisi pubblicata su Transactions of the ACL, hanno documentato il fenomeno "lost in the middle": le informazioni posizionate nella parte centrale di un contesto lungo vengono utilizzate meno efficacemente dal modello rispetto a quelle poste all'inizio o alla fine. Il dato ha implicazioni dirette per la strutturazione del prompt: posizionare il contesto critico in posizione iniziale (subito dopo il task) o terminale migliora la performance.
2.3 Output (): la componente più sensibile
Yin et al. [13], in un contributo presentato ad ACL 2023, hanno condotto un'analisi sistematica della sensibilità dei modelli alle diverse componenti dell'istruzione. Il risultato principale è che la rimozione delle specifiche sull'output — in particolare le label e la descrizione del formato atteso della risposta — produce il calo di performance più marcato. Inoltre, un algoritmo di compressione automatica ha dimostrato che il 60% dei token di un'istruzione può essere rimosso senza degradazione della performance, a condizione che le specifiche sull'output vengano preservate.
Il dato è notevole e talvolta controintuitivo: la componente è quella a cui il modello è più sensibile. Un prompt con un task vago ma specifiche di output chiare può produrre risultati migliori di un prompt con un task dettagliato ma nessuna indicazione sull'output atteso. In termini formali:
dove rappresenta la qualità della risposta e le derivate parziali indicano la sensibilità rispetto a ciascuna componente. L'ordinamento è approssimativo e dipende dal tipo di task, ma il primato della componente è robusto attraverso i benchmark analizzati.
Nori et al. [14], in uno studio di Microsoft Research, hanno dimostrato che il metodo Medprompt — basato su una specifica strutturata del processo e dell'output atteso — ha consentito a GPT-4 di superare modelli specialistici come Med-PaLM 2 con una riduzione degli errori del 27% su MedQA, superando per la prima volta il 90% di accuratezza. I risultati si sono generalizzati a ingegneria elettrica, machine learning, filosofia, contabilità, diritto e psicologia clinica.
2.4 Format (): struttura con cautela
La specifica del formato è la componente che richiede il bilanciamento più delicato. Da un lato, indicare il formato desiderato (tabella, elenco, paragrafo, JSON) riduce l'ambiguità e aumenta l'usabilità dell'output. Wei et al. [2] hanno dimostrato che la richiesta di passaggi intermedi strutturati (chain-of-thought) — che è di fatto una specifica di formato del processo di ragionamento — migliora significativamente le prestazioni su task di ragionamento.
Dall'altro lato, Tam et al. [15], in uno studio presentato a EMNLP 2024, hanno documentato che l'imposizione di vincoli di formato troppo rigidi (ad esempio, schemi JSON stretti) degrada le capacità di ragionamento del modello. Il risultato suggerisce che la componente deve guidare la struttura dell'output senza imbrigliarla meccanicamente.
La raccomandazione operativa è dunque la seguente: specificare il formato in termini di struttura logica (sezioni, tabelle, elenchi) piuttosto che di sintassi stretta (schemi JSON rigidi con campi obbligatori), a meno che il caso d'uso non lo richieda esplicitamente.
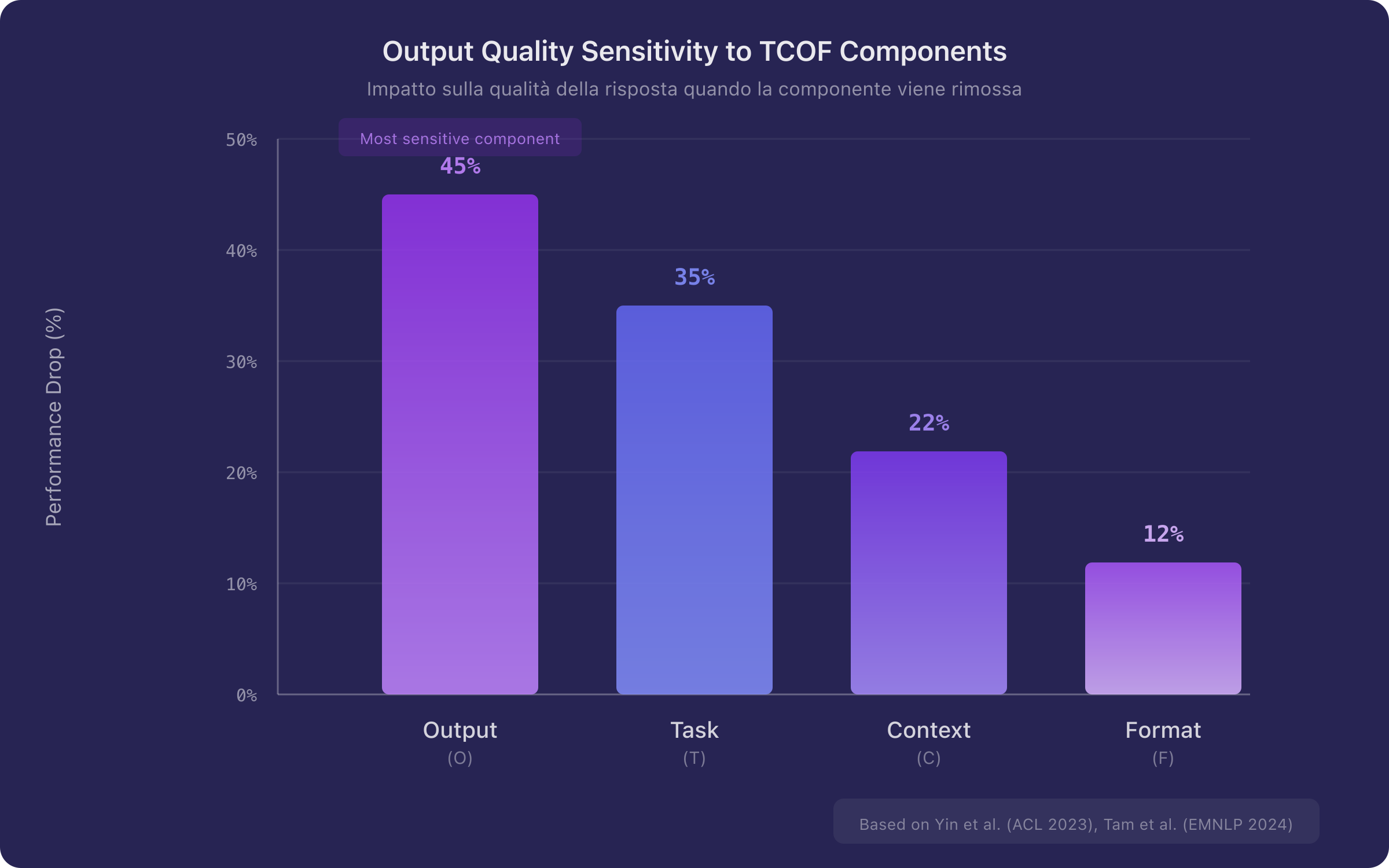
Figura 2. Rappresentazione qualitativa della sensibilità della qualità dell'output alle quattro componenti TCOF. La componente Output (O) mostra la sensibilità maggiore, seguita da Task (T), Context (C) e Format (F). L'ordinamento si basa sui dati di Yin et al. [13] e Tam et al. [15].
3. Un Modello Formale di Qualità Basato su TCOF
3.1 Definizione del modello
Sulla base delle evidenze presentate nella Sezione 2, si propone un modello di qualità del prompt definito come somma pesata delle quattro componenti:
dove rappresenta il punteggio della -esima componente e il peso associato, con il vincolo .
3.2 Calibrazione dei pesi
I pesi sono derivati dalle evidenze sperimentali secondo il seguente ragionamento:
| Componente | Peso | Giustificazione |
|---|---|---|
| Task () | 0,30 | Condizione necessaria per la generazione [7][8][10] |
| Context () | 0,20 | Riduttore di entropia, effetto moderato ma consistente [1][3][12] |
| Output () | 0,30 | Massima sensibilità del modello [13][14] |
| Format () | 0,20 | Struttura utile ma vincoli rigidi controproducenti [2][15] |
Si noti che, a differenza del modello a cinque componenti proposto in [16], il modello TCOF assegna un peso paritetico a Task e Output (0,30 ciascuno), riflettendo le evidenze di Yin et al. [13] sulla sensibilità critica del modello alle specifiche dell'output. Il contesto e il formato ricevono ciascuno un peso di 0,20.
3.3 Soglia di qualità
Si definisce una soglia di qualità minima basata sull'evidenza che la presenza di almeno tre componenti su quattro è sufficiente a produrre un output utilizzabile nella maggioranza dei casi. Se ogni componente presente riceve un punteggio conservativo di (su 5):
dove è il peso medio delle tre componenti con punteggio più alto. In pratica, un prompt con almeno tre componenti TCOF ben formulate produce risultati apprezzabilmente migliori di un prompt non strutturato.

Figura 3. Distribuzione dei pesi nel modello . Task e Output condividono il peso maggiore (30% ciascuno), riflettendo il loro impatto dominante sulla qualità della risposta. Context e Format contribuiscono ciascuno per il 20%.
4. Interazioni tra Componenti
4.1 Sinergie
Le quattro componenti TCOF non operano in modo indipendente. Si osservano interazioni sinergiche significative:
T × C (Task × Context): un task preciso amplifica l'effetto del contesto. Il contesto "settore alimentare biologico, PMI italiana, 12 dipendenti" è utile solo se il task lo attiva ("elabora un piano marketing"), altrimenti rimane informazione inerte. Zamfirescu-Pereira et al. [17] hanno documentato come gli utenti non esperti tendano a fornire contesto senza un task chiaro, ottenendo risposte informative ma non azionabili.
O × F (Output × Format): le specifiche dell'output e del formato sono complementari. La richiesta "includi KPI misurabili" () e la richiesta "organizza in tabella" () producono congiuntamente un risultato più utilizzabile di ciascuna specifica presa singolarmente.
T × O (Task × Output): questa è l'interazione più critica. Come evidenziato da Yin et al. [13], la combinazione di un task chiaro con specifiche di output precise produce il massimo guadagno di qualità. In termini formali, si tratta di un'interazione super-additiva:
4.2 Conflitti
Non tutte le interazioni sono positive. Tam et al. [15] hanno documentato il conflitto in task di ragionamento: un task che richiede ragionamento complesso combinato con un formato rigido (JSON con schema fisso) produce prestazioni inferiori rispetto allo stesso task senza vincoli di formato. La raccomandazione è di rilassare i vincoli di formato quando il task richiede ragionamento multi-step.
4.3 Ordinamento posizionale
Liu et al. [12] hanno dimostrato che la posizione delle informazioni nel prompt influisce sulla loro utilizzazione da parte del modello. L'acronimo TCOF riflette un ordinamento posizionale ottimale:
- Task in apertura — l'istruzione principale è l'elemento che orienta l'intera generazione
- Context subito dopo — le informazioni di sfondo condizionano l'interpretazione del task
- Output in posizione centrale-avanzata — le specifiche sull'output guidano la fase generativa
- Format in chiusura — i vincoli strutturali vengono applicati durante la formattazione finale
Questo ordinamento non è un obbligo rigido, ma riflette il principio documentato in [12]: le informazioni all'inizio e alla fine del prompt ricevono maggiore attenzione, mentre quelle centrali tendono ad essere sotto-utilizzate.
5. Applicazione Operativa
5.1 Protocollo TCOF in quattro fasi
Si propone un protocollo operativo per l'applicazione sistematica del framework:
Fase 1 — Task: formulare l'istruzione principale usando un verbo d'azione specifico. Evitare verbi vaghi ("parlami di", "aiutami con") a favore di verbi precisi ("analizza", "confronta", "elabora", "sintetizza", "valuta").
Fase 2 — Context: identificare le informazioni di sfondo necessarie rispondendo a: chi è il destinatario? Qual è il dominio? Quali vincoli esterni esistono? Quale conoscenza pregressa è necessaria?
Fase 3 — Output: specificare le caratteristiche attese della risposta: cosa deve includere, quale livello di dettaglio, quali criteri di qualità. Questa è la fase a cui dedicare la maggiore attenzione, sulla base delle evidenze di Yin et al. [13].
Fase 4 — Format: indicare la struttura desiderata (sezioni, tabelle, elenchi) e i vincoli di lunghezza. Evitare specifiche di formato troppo rigide per task che richiedono ragionamento.
5.2 Esempio applicativo: tre livelli di strutturazione
Si illustra l'effetto cumulativo dell'aggiunta progressiva delle componenti TCOF:
Solo Task ():
Analizza le performance di vendita del trimestre.
Task + Context ():
Analizza le performance di vendita del Q3 2025 per un e-commerce di abbigliamento sportivo con fatturato annuo di 2M euro. Il trimestre precedente ha registrato un calo del 12% rispetto al Q2.
TCOF completo ():
[T] Analizza le performance di vendita del Q3 2025 e identifica le cause principali della variazione rispetto al trimestre precedente.
[C] L'azienda è un e-commerce di abbigliamento sportivo con fatturato annuo di 2M euro. Il Q2 2025 ha registrato un calo del 12% rispetto al Q1, attribuito a una riduzione del traffico organico e a problemi di approvvigionamento sulla linea running.
[O] L'analisi deve includere: (1) confronto quantitativo Q3 vs Q2 per le prime 5 categorie di prodotto; (2) identificazione dei 3 fattori principali che spiegano la variazione; (3) valutazione dell'impatto di ciascun fattore; (4) raccomandazioni operative per il Q4 con stima dell'impatto atteso.
[F] Struttura la risposta in 4 sezioni numerate. Per il confronto tra categorie usa una tabella. Per le raccomandazioni usa un elenco numerato con priorità (alta/media/bassa). Lunghezza: 800-1.000 parole.
La progressione illustra come ciascuna componente aggiuntiva riduca lo spazio delle risposte possibili e aumenti la probabilità di ottenere un output direttamente utilizzabile.
5.3 Anti-pattern: errori comuni nell'applicazione
L'applicazione del framework TCOF non è immune da errori. La tabella seguente classifica i più frequenti:
| Anti-pattern | Componente | Descrizione | Esempio |
|---|---|---|---|
| Task implicito | L'azione richiesta non è esplicitata | "Il marketing digitale per le PMI" (non è un task) | |
| Contesto generico | Informazioni di sfondo troppo vaghe per essere utili | "Un'azienda italiana" (quale settore? dimensione? mercato?) | |
| Output non verificabile | Le specifiche non consentono di valutare la risposta | "Dammi una buona analisi" (cosa rende "buona" l'analisi?) | |
| Formato sovra-specificato | Vincoli strutturali talmente rigidi da imbrigliare il ragionamento | "Rispondi SOLO in JSON con esattamente 7 campi" per un task analitico | |
| Inversione posizionale | Il contesto precede il task, diluendone l'effetto | Due paragrafi di background prima della richiesta effettiva |
6. Gestione Sistematica dei Prompt TCOF
6.1 Dal prompt singolo alla libreria strutturata
L'applicazione sistematica del framework TCOF a un numero crescente di attività produce un effetto collaterale desiderabile: i prompt diventano modulari e riutilizzabili. Un prompt strutturato secondo TCOF si presta naturalmente alla categorizzazione (per tipo di task), al tagging (per dominio di contesto), e al versionamento (le modifiche riguardano tipicamente una sola componente per iterazione).
Liu et al. [18], nella survey pubblicata su ACM Computing Surveys, hanno evidenziato come il prompting sia diventato un paradigma centrale nell'interazione con i modelli linguistici, e come la gestione efficace dei prompt rappresenti un fattore critico per la produttività. La sfida non è scrivere un singolo buon prompt, ma costruire e mantenere una libreria di prompt strutturati che evolva nel tempo.
6.2 Versionamento e qualità
Il framework TCOF facilita il raffinamento iterativo perché rende esplicite le dimensioni di miglioramento. Quando un prompt non produce l'output desiderato, la diagnosi può essere condotta componente per componente:
- Se l'output è off-topic → problema nella componente
- Se l'output è generico → problema nella componente
- Se l'output è incompleto o superficiale → problema nella componente
- Se l'output è destrutturato o illeggibile → problema nella componente
Questa proprietà diagnostica rende TCOF particolarmente adatto a sistemi di gestione che supportano il versionamento: ogni versione del prompt può essere annotata con la componente modificata e il razionale del cambiamento.
6.3 Valutazione automatica
Il modello si presta all'implementazione in sistemi di valutazione automatica della qualità del prompt. Un sistema che analizza la presenza e la qualità delle quattro componenti può fornire un punteggio oggettivo e indicazioni di miglioramento mirate.
La piattaforma Keep My Prompts implementa un sistema di Prompt Score basato su criteri analoghi a quelli del framework TCOF: chiarezza e specificità (che mappa sulla componente ), contesto (), struttura TCOF (), role prompting (un'estensione di ), few-shot examples e chain-of-thought (tecniche complementari). Il punteggio viene calcolato automaticamente su una scala 1-5 con pesi differenziati, fornendo sia un indicatore sintetico sia suggerimenti operativi per il miglioramento. Per i team di lavoro sono disponibili piani collaborativi che consentono la condivisione di prompt strutturati con tracciamento delle versioni per autore.
7. TCOF e Tecniche Avanzate: un Rapporto di Complementarità
7.1 TCOF come prerequisito
Il framework TCOF non sostituisce le tecniche avanzate di prompting — le abilita. Si consideri la relazione tra TCOF e tre tecniche fondamentali:
Chain-of-Thought [2]: il CoT è una tecnica che opera sulla componente , specificando che l'output deve includere passaggi intermedi di ragionamento. Senza un task () chiaramente definito, il ragionamento step-by-step non ha un obiettivo verso cui convergere.
Few-Shot [1]: gli esempi forniti nel prompt sono un'estensione della componente , che illustrano il pattern atteso attraverso coppie input-output. Senza specifiche di output (), gli esempi possono essere interpretati in modo ambiguo dal modello.
Decomposed Prompting [4]: Khot et al. hanno dimostrato che la decomposizione di task complessi in sotto-task più semplici migliora le prestazioni. La decomposizione opera sulla componente , ma richiede che le specifiche di output () siano definite per ciascun sotto-task.
7.2 Schema di compatibilità
| Tecnica avanzata | Componente TCOF su cui opera | Prerequisito TCOF |
|---|---|---|
| Chain-of-Thought | (processo di output) | chiaro |
| Few-Shot | (esempi come contesto) | definito |
| Role Prompting | (persona come contesto) | specifico |
| Decomposed Prompting | (scomposizione del task) | per ogni sotto-task |
| Self-Consistency | (formato di aggregazione) | completi |
8. Conclusioni
8.1 Sintesi
Il presente articolo ha proposto il framework TCOF (Task, Context, Output, Format) come struttura fondamentale per la costruzione di prompt efficaci. Le evidenze sperimentali, tratte da contributi presentati a NeurIPS [2][10], ICLR [7], ACL [8][13], NAACL [3], EMNLP [11][15] e altri, convergono su tre conclusioni principali:
-
La struttura del prompt è il principale determinante della qualità dell'output. Non la lunghezza, non la sofisticazione lessicale, ma la presenza di componenti funzionali discrete e ben definite.
-
La componente Output () è quella a cui il modello è più sensibile, seguita dal Task (). Il 60% dei token di un'istruzione può essere rimosso senza degradazione, a condizione che le specifiche di output siano preservate [13].
-
Il framework TCOF è complementare, non alternativo, alle tecniche avanzate. Chain-of-thought, few-shot e decomposed prompting producono i migliori risultati quando applicati a prompt già strutturati secondo TCOF.
8.2 Raccomandazione operativa
Sulla base dell'analisi condotta, si formula la seguente raccomandazione: prima di inviare qualsiasi prompt a un modello linguistico, si verifichi che contenga almeno le componenti Task e Output del framework TCOF. Queste due componenti, che condividono il peso maggiore nel modello (0,30 ciascuna, per un totale del 60%), rappresentano la soglia minima per ottenere risultati utilizzabili al primo tentativo.
L'aggiunta progressiva di Context e Format eleva ulteriormente la qualità, ma il rapporto costi-benefici più favorevole si ottiene assicurando la presenza delle prime due componenti.
Riferimenti Bibliografici
[1] T. Brown et al., "Language Models are Few-Shot Learners," Advances in Neural Information Processing Systems, vol. 33, pp. 1877-1901, 2020. arXiv: 2005.14165.
[2] J. Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," Advances in Neural Information Processing Systems, vol. 35, 2022. arXiv: 2201.11903.
[3] A. Kong et al., "Better Zero-Shot Reasoning with Role-Play Prompting," Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024. arXiv: 2308.07702.
[4] T. Khot et al., "Decomposed Prompting: A Modular Approach for Solving Complex Tasks," Proceedings of the International Conference on Learning Representations (ICLR), 2023. arXiv: 2210.02406.
[5] S. Schulhoff et al., "The Prompt Report: A Systematic Survey of Prompt Engineering Techniques," arXiv preprint, 2024. arXiv: 2406.06608.
[6] Anthropic, "Use XML Tags to Structure Your Prompts," Claude Documentation, 2024. Disponibile: https://docs.anthropic.com/en/build-with-claude/prompt-engineering/use-xml-tags
[7] Y. Zhou et al., "Large Language Models Are Human-Level Prompt Engineers," Proceedings of the International Conference on Learning Representations (ICLR), 2023. arXiv: 2211.01910.
[8] S. Mishra et al., "Reframing Instructional Prompts to GPTk's Language," Findings of the Association for Computational Linguistics: ACL 2022, pp. 589-612, 2022. arXiv: 2109.07830.
[9] S. M. Bsharat, A. Myrzakhan, Z. Shen, "Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4," arXiv preprint, 2024. arXiv: 2312.16171.
[10] T. Kojima et al., "Large Language Models are Zero-Shot Reasoners," Advances in Neural Information Processing Systems, vol. 35, 2022. arXiv: 2205.11916.
[11] M. Zheng et al., "When 'A Helpful Assistant' Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models," Findings of the Association for Computational Linguistics: EMNLP 2024, 2024. arXiv: 2311.10054.
[12] N. F. Liu et al., "Lost in the Middle: How Language Models Use Long Contexts," Transactions of the Association for Computational Linguistics, vol. 12, pp. 157-173, 2024. DOI: 10.1162/tacl_a_00638.
[13] F. Yin et al., "Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning," Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), Toronto, 2023. arXiv: 2306.01150.
[14] H. Nori et al., "Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine," arXiv preprint, 2023. arXiv: 2311.16452.
[15] Z. R. Tam et al., "Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models," EMNLP 2024 Industry Track, 2024. arXiv: 2408.02442.
[16] S. Petrucci, "Come Scrivere Prompt Efficaci per ChatGPT: Guida Pratica con Approccio Scientifico," Keep My Prompts Blog, 2025. Disponibile: https://www.keepmyprompts.com/blog/it/come-scrivere-prompt-efficaci-chatgpt
[17] J. D. Zamfirescu-Pereira et al., "Why Johnny Can't Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts," Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 2023. DOI: 10.1145/3544548.3581388.
[18] P. Liu et al., "Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing," ACM Computing Surveys, vol. 55, no. 9, pp. 1-35, 2023. DOI: 10.1145/3560815.